LFM | Meta - LLaMA
- Related Project: private
- Category: Paper Review
- Date: 2023-08-07
LLaMA: Open and Efficient Foundation Language Models
- url: https://arxiv.org/abs/2302.13971
- pdf: https://arxiv.org/pdf/2302.13971
- abstract: We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Release Date: 2023.02
- 7B to 65B parameters
- Trained on public datasets
- Competitive with larger models
Release Date: 2023.07
- 7B to 70B parameters
- Fine-tuned for dialogue
- Improved safety and helpfulness
Release Date: 2024.07
- 7B to 405B parameters, 128K context window
- Multilingual, coding, reasoning, tool usage
Contents
- LLaMA: Open and Efficient Foundation Language Models
TL;DR
- 대규모 언어모델 훈련: 고성능 모델 훈련을 위한 대규모 데이터셋 사용
- 효율적인 모델 아키텍처: 최적화된 아키텍처를 통한 효율적 인퍼런스
- 개방형 데이터 활용: 공개적으로 이용 가능한 데이터만을 사용하여 연구 및 개발을 촉진
개요
[서론 및 배경]
이 연구는 대규모 언어모델(LLM)의 효율적인 훈련과 인퍼런스 성능 향상에 중점을 두고 있습니다. 최근 연구에 따르면, 모델의 크기를 단순히 증가시키는 것보다는, 적절한 데이터와 효율적인 아키텍처를 사용하여 더 작은 모델을 더 오래 훈련시키는 것이 비용 효율적일 수 있음을 시사합니다. 이에 본 연구에서는 퍼블릭 데이터를 사용하여 경쟁력 있는 성능을 갖춘 LLM을 지향합니다.
[방법]
데이터 준비 및 전처리
- 사용된 데이터셋: Common Crawl, C4, Github, Wikipedia 등
- 데이터 토큰화: Byte Pair Encoding (BPE)을 사용하여 데이터를 토큰화
- 수학적 접근: 토큰화된 데이터셋의 크기는 약 1.4T 토큰
모델 아키텍처
- 기본 구조: Transformer 아키텍처를 기반으로 하며, 몇 가지 주요 개선 사항을 포함
- 수학적 설명:
- Pre-normalization: 각 서브레이어의 입력을 정규화하여 학습 안정성을 높임.
- SwiGLU 활성화 함수: 기존의 ReLU를 SwiGLU로 대체하여 성능을 개선
최적화 및 효율적 구현
- Optimizer: AdamW, $\beta_1=0.9$, $\beta_2=0.95$.
- Learning rate scheduling: Cosine learning rate 스케줄을 사용
- 효율적인 실행: Causal multi-head attention을 최적화하여 메모리 사용량과 런타임을 줄임.
[성능 평가 및 벤치마크]
- 다양한 벤치마크에 대한 성능 평가를 통해 모델의 효과를 증명하고, LLM의 성능 최적화를 위해 다음과 같은 수학적 접근을 사용합니다.
- [Learning rate scheduling] Cosine 스케줄: 학습률 $\eta(t)$는 $\eta_{max} \cdot (1 + \cos(\pi t / T)) / 2$로 조절됩니다. ($t$는 현재 에포크 수, $T$는 총 에포크 수, $\eta_{max}$는 최대 학습률)
- [효율적인 어텐션 메커니즘] Causal multi-head attention: 이는 계산 복잡성을 줄이기 위해 attention 가중치를 저장하지 않고, masked attention 점수만을 계산
1. 서론
대규모 언어모델(Large Language Models, LLMs)은 방대한 텍스트 데이터셋에서 학습되어 놀라운 few-shot 학습 능력을 보여주고 있습니다. 이런 능력은 모델의 크기가 충분히 커졌을 때 처음 나타났으며, 이로 인해 많은 연구자들이 모델의 규모를 더욱 키우는 데 주력해왔습니다.
하지만 최근 Hoffmann et al. (2022)의 연구에 따르면, 주어진 컴퓨팅 예산 내에서 최고의 성능을 달성하는 것은 가장 큰 모델이 아닌, 더 많은 데이터로 학습된 smaller 모델이라는 것이 밝혀졌습니다. 이는 기존의 “더 큰 모델이 더 나은 성능을 낸다”는 가정에 의문을 제기합니다.
Hoffmann et al.의 scaling laws는 특정 학습 컴퓨팅 예산에 대해 데이터셋과 모델 크기를 최적으로 조정하는 방법을 결정하는 데 초점을 맞추고 있습니다. 그러나 이 접근 방식은 대규모로 언어 모델을 서비스할 때 중요해지는 인퍼런스(inference) 예산을 고려하지 않았습니다.
실제 서비스 환경에서는 특정 성능 수준을 달성하는 데 있어 가장 빠르게 학습되는 모델보다는 인퍼런스 속도가 가장 빠른 모델이 선호됩니다. 예를 들어, Hoffmann et al.은 200B 토큰으로 10B 모델을 학습하는 것을 추천했지만, 본 연구에서는 7B 모델의 성능이 1T 토큰 이후에도 계속 향상된다는 것을 발견했습니다.
이런 배경에서, 본 연구의 주요 목표는 다양한 인퍼런스 예산에서 좋은 성능을 달성할 수 있는 일련의 언어 모델을 학습하는 것입니다. 이를 위해 일반적으로 사용되는 것보다 더 많은 토큰으로 모델을 학습시켰습니다.
결과적으로 개발된 LLaMA(Large Language Model Meta AI) 모델은 7B에서 65B 파라미터 범위를 가지며, 기존의 최고 성능 LLM들과 비교하여 경쟁력 있는 성능을 보여줍니다. 예를 들어, LLaMA-13B는 GPT-3보다 10배 작음에도 불구하고 대부분의 벤치마크에서 더 우수한 성능을 나타냅니다. 이는 단일 GPU에서도 실행 가능한 모델로, LLM 연구의 접근성을 높일 것으로 기대됩니다.
상위 모델인 65B 파라미터 모델은 Chinchilla나 PaLM-540B와 같은 최고 성능의 대규모 언어모델들과 경쟁력 있는 성능을 보입니다. 특히 주목할 점은 LLaMA가 Chinchilla, PaLM, GPT-3와는 달리 오직 공개적으로 이용 가능한 데이터만을 사용했다는 것입니다. 이는 LLaMA의 오픈소스 호환성을 가능케 하며, 기존의 많은 모델들이 비공개 또는 문서화되지 않은 데이터(“Books-2TB” 또는 “Social media conversations” 등)에 의존하는 것과 대조됩니다.
물론 OPT, GPT-NeoX, BLOOM, GLM과 같은 오픈소스 모델들도 있지만, 이들 중 PaLM-62B나 Chinchilla와 경쟁력 있는 성능을 보이는 모델은 없었습니다.
2. 접근 방법
LLaMA의 학습 방법은 기존의 연구들(Brown et al., 2020; Chowdhery et al., 2022)과 유사하며, Chinchilla scaling laws (Hoffmann et al., 2022)에서 영감을 받았습니다. 구체적으로, 대규모 트랜스포머 모델을 표준 최적화 기법을 사용하여 방대한 양의 텍스트 데이터에서 학습시켰습니다.
2.1 Pre-training dataset
LLaMA의 training dataset셋은 다양한 도메인을 포함하는 여러 소스의 혼합으로 구성되었습니다. 주로 다른 LLM들을 학습시키는 데 사용된 데이터 소스를 재사용했지만, 오직 공개적으로 이용 가능하고 오픈소스와 호환되는 데이터만을 사용했습니다. 이에 따라 다음과 같은 데이터 혼합과 각각의 비율이 학습 세트에 포함되었습니다.
- English CommonCrawl [67%]: 2017년부터 2020년까지의 5개 CommonCrawl 덤프를 CCNet 파이프라인으로 전처리했습니다. 이 과정에서 줄 단위 중복 제거, fastText 선형 분류기를 이용한 언어 식별, n-gram 언어 모델을 통한 저품질 콘텐츠 필터링 등이 수행되었습니다. 추가로 Wikipedia 참조로 사용된 페이지와 무작위로 샘플링된 페이지를 분류하는 선형 모델을 학습시켜, 참조로 분류되지 않은 페이지들을 제거했습니다.
- C4 [15%]: 탐색적 실험에서 다양한 전처리된 CommonCrawl 데이터셋을 사용하면 성능이 향상됨을 관찰했습니다. 따라서 공개적으로 이용 가능한 C4 데이터셋(Raffel et al., 2020)을 포함시켰습니다. C4의 전처리도 중복 제거와 언어 식별 단계를 포함하며, 주요 차이점은 품질 필터링이 주로 구두점 존재 여부나 웹페이지의 단어 및 문장 수와 같은 휴리스틱에 의존한다는 것입니다.
- Github [4.5%]: Google BigQuery에서 제공하는 공개 GitHub 데이터셋을 사용했습니다. Apache, BSD, MIT 라이선스로 배포된 프로젝트만을 선택했으며, 줄 길이나 영숫자 문자 비율 등의 휴리스틱을 기반으로 저품질 파일을 필터링하고, 정규 표현식을 사용하여 헤더와 같은 상용구를 제거했습니다. 최종적으로 파일 수준에서 정확한 일치를 기준으로 중복을 제거했습니다.
- Wikipedia [4.5%]: 2022년 6월부터 8월까지의 Wikipedia 덤프를 추가했으며, 라틴 또는 키릴 문자를 사용하는 20개 언어를 포함합니다. 하이퍼링크, 주석, 기타 서식 상용구를 제거하는 처리를 수행했습니다.
- Gutenberg and Books3 [4.5%]: 두 가지 도서 코퍼스를 포함했습니다. 공공 도메인 도서를 포함하는 Gutenberg Project와 대규모 언어모델 학습을 위한 공개 데이터셋인 ThePile의 Books3 섹션입니다. 도서 수준에서 중복을 제거하여 90% 이상 내용이 겹치는 도서들을 제거했습니다.
- ArXiv [2.5%]: 과학적 데이터를 데이터셋에 추가하기 위해 arXiv Latex 파일을 처리했습니다. Lewkowycz et al. (2022)의 방법을 따라 첫 번째 섹션 이전의 모든 내용과 참고문헌을 제거했습니다. 또한 .tex 파일의 주석을 제거하고, 논문 간의 일관성을 높이기 위해 사용자가 작성한 정의와 매크로를 인라인으로 확장했습니다.
- Stack Exchange [2%]: 다양한 도메인을 다루는 고품질 질문-답변 웹사이트인 Stack Exchange의 덤프를 포함했습니다. 28개의 가장 큰 웹사이트의 데이터를 유지하고, 텍스트에서 HTML 태그를 제거했으며, 답변을 점수(높은 순에서 낮은 순)에 따라 정렬했습니다.
토크나이저: 데이터를 토큰화하기 위해 SentencePiece 구현을 사용하여 바이트페어 인코딩(BPE) 알고리즘을 적용했습니다. 특히 모든 숫자를 개별 숫자로 분할하고, 알려지지 않은 UTF-8 문자를 분해하기 위해 바이트로 폴백합니다.
전체 training dataset셋은 토큰화 후 약 1.4T 토큰을 포함합니다. 대부분의 training dataset에서 각 토큰은 학습 중 한 번만 사용되지만, Wikipedia와 Books 도메인에 대해서는 약 두 번의 에포크를 수행했습니다.
2.2 아키텍처
최근의 대규모 언어모델 연구를 따라, LLaMA의 네트워크는 트랜스포머 아키텍처(Vaswani et al., 2017)를 기반으로 합니다. 이후 제안된 다양한 개선 사항들을 활용했으며, 이는 PaLM과 같은 다른 모델들에서도 사용되었습니다. 원래의 아키텍처와의 주요 차이점은 다음과 같습니다.
- Pre-normalization [GPT3]: 학습 안정성을 향상시키기 위해, 각 트랜스포머 서브 레이어의 출력을 정규화하는 대신 입력을 정규화합니다. Zhang and Sennrich (2019)가 도입한 RMSNorm 정규화 함수를 사용합니다.
- SwiGLU activation function [PaLM]: 성능 향상을 위해 ReLU 비선형성을 Shazeer (2020)가 도입한 SwiGLU 활성화 함수로 대체했습니다. PaLM에서는 4d 차원을 사용했지만, LLaMA에서는 2/3d 차원을 사용합니다.
- Rotary Embeddings [GPTNeo]: 절대 위치 임베딩을 제거하고, 대신 Su et al. (2021)이 도입한 rotary positional embeddings (RoPE)를 네트워크의 각 레이어에 추가했습니다.
이런 아키텍처 변경을 통해 LLaMA는 기존 모델들보다 더 효율적이고 성능이 우수한 언어 모델을 구현할 수 있었습니다.
| 파라미터 수 | 차원 | 헤드 수 | 레이어 수 | 학습률 | 배치 크기 | 토큰 수 |
|---|---|---|---|---|---|---|
| 6.7B | 4096 | 32 | 32 | 3.0e-4 | 4M | 1.0T |
| 13.0B | 5120 | 40 | 40 | 3.0e-4 | 4M | 1.0T |
| 32.5B | 6656 | 52 | 60 | 1.5e-4 | 4M | 1.4T |
| 65.2B | 8192 | 64 | 80 | 1.5e-4 | 4M | 1.4T |
이런 모델 구성을 통해 LLaMA는 다양한 크기의 모델을 효율적으로 학습하고, 각 모델 크기에 최적화된 성능을 달성할 수 있었습니다.
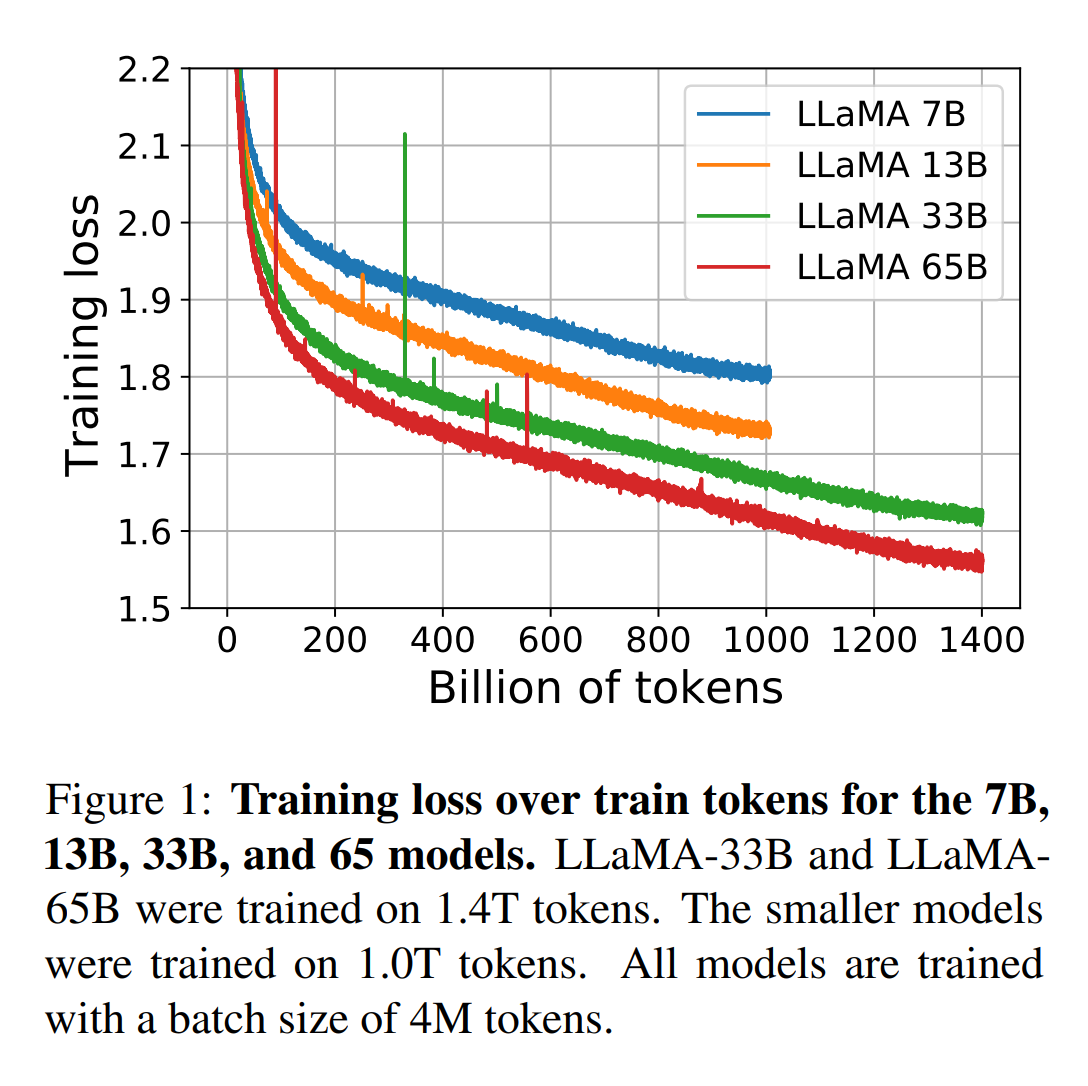
학습 과정에서의 손실(training loss) 추이를 살펴보면, 모델 크기에 따른 성능 향상을 명확히 확인할 수 있습니다. Figure 1에서 보여지는 바와 같이, 7B, 13B, 33B, 65B 모델의 학습 손실이 토큰 수에 따라 어떻게 변화하는지 나타내고 있습니다.
\[L_{train} = f(T)\]상기 식에서 $L_{train}$은 학습 손실, $T$는 학습된 토큰의 수를 나타냅니다.
모든 모델은 4M 토큰의 배치 크기로 학습되었으며, 33B와 65B 모델은 1.4T 토큰으로, 작은 모델들은 1.0T 토큰으로 학습되었습니다. 그래프를 통해 다음과 같은 중요한 관찰을 할 수 있습니다.
- 모델 크기가 증가할수록 전반적인 학습 손실이 감소합니다. 이는 더 큰 모델이 데이터의 복잡한 패턴을 더 잘 포착할 수 있음을 시사합니다.
- 모든 모델에서 학습 토큰 수가 증가함에 따라 손실이 지속적으로 감소하는 경향을 보입니다. 이는 더 많은 데이터로 학습할수록 모델의 성능이 향상됨을 의미합니다.
- 큰 모델(33B, 65B)의 경우, 1.0T 토큰 이후에도 손실이 계속 감소하는 것을 볼 수 있습니다. 이는 Hoffmann et al. (2022)의 scaling laws를 넘어서는 결과로, 더 큰 모델에 더 많은 데이터를 학습시키는 것이 여전히 효과적임을 보여줍니다.
이런 관찰 결과는 LLaMA의 학습 전략이 효과적이며, 특히 큰 모델에서 더 많은 데이터로 학습하는 것이 성능 향상에 도움이 된다는 것을 입증합니다.
모델의 성능을 수학적으로 표현하면 다음과 같은 관계를 인퍼런스할 수 있습니다.
\[P(M, T) = \alpha \log(M) + \beta \log(T) + \gamma\]상기 식에서 $P$는 모델의 성능, $M$은 모델의 파라미터 수, $T$는 학습 토큰 수, $\alpha$, $\beta$, $\gamma$는 상수입니다.
이 식은 모델의 성능이 모델 크기의 로그와 training dataset 양의 로그에 비례하여 증가한다는 것을 나타냅니다. 이는 Figure 1의 결과와 일치하며, 모델 크기와 training dataset 양을 증가시킴으로써 성능을 향상시킬 수 있다는 것을 보여줍니다.
LLaMA의 주요 기여 중 하나는 이런 scaling laws를 실제 모델 학습에 효과적으로 적용했다는 점입니다. 특히, 기존의 방식대로 단순히 모델 크기를 키우는 것이 아니라, 적절한 크기의 모델에 더 많은 데이터를 학습시키는 전략을 채택했습니다. 이는 인퍼런스 시 계산 효율성을 고려한 접근 방식으로, 실제 서비스 환경에서 큰 이점을 제공할 수 있습니다.
더불어, LLaMA는 공개 데이터만을 사용하여 학습되었다는 점에서 큰 의의가 있습니다. 이는 연구의 재현성과 모델의 투명성을 높이는 데 기여하며, 향후 LLM 연구의 민주화에 중요한 역할을 할 것으로 기대됩니다.
LLaMA의 아키텍처 개선 사항들 (pre-normalization, SwiGLU 활성화 함수, rotary embeddings)은 각각 다음과 같은 수학적 배경을 갖고 있습니다.
- Pre-normalization 레이어 정규화를 서브레이어의 출력이 아닌 입력에 적용합니다.
상기 식에서 $\mu$와 $\sigma$는 각각 입력의 평균과 표준편차, $\gamma$와 $\beta$는 학습 가능한 파라미터, $\epsilon$은 수치 안정성을 위한 작은 상수입니다.
- SwiGLU 활성화 함수 기존의 ReLU를 대체하여 사용됩니다.
\(\text{SwiGLU}(x, W, V, \beta) = \text{Swish}_\beta(xW) \otimes (xV)\) \(\text{Swish}_\beta(x) = x \cdot \sigma(\beta x)\)
상기 식에서 $\sigma$는 시그모이드 함수, $\beta$는 학습 가능한 파라미터입니다.
- Rotary Embeddings (RoPE) 위치 정보를 임베딩하는 새로운 방식을 제공합니다.
상기 식에서 $x_i$는 임베딩 벡터, $m$은 차원 인덱스, $\theta$는 위치에 따른 각도입니다.
이런 수학적 기반을 통해 LLaMA는 기존 트랜스포머 모델의 성능을 개선하고, 효율적인 학습 및 인퍼런스를 가능케 했습니다. 특히, 이런 개선사항들은 모델의 표현력을 높이고 학습의 안정성을 향상시키는 데 기여했습니다.
2.3 Optimizer
LLaMA 모델들은 AdamW optimizer(Loshchilov and Hutter, 2017)를 사용하여 학습되었습니다. 주요 하이퍼파라미터는 다음과 같습니다.
- β1 = 0.9, β2 = 0.95
- 코사인 학습률 스케줄 사용 (최종 학습률은 최대 학습률의 10%)
- 가중치 감쇠(weight decay) 0.1
- 그래디언트 클리핑(gradient clipping) 1.0
- 2,000 스텝의 웜업(warmup) 사용
모델 크기에 따라 학습률과 배치 크기를 조정했습니다(자세한 내용은 Table 2 참조).
AdamW optimizer의 수학적 표현은 다음과 같습니다.
\(m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t\) \(v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2\) \(\hat{m_t} = \frac{m_t}{1 - \beta_1^t}\) \(\hat{v_t} = \frac{v_t}{1 - \beta_2^t}\) \(\theta_t = \theta_{t-1} - \eta \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} - \eta \lambda \theta_{t-1}\)
상기 식에서 $g_t$는 현재 그래디언트, $m_t$와 $v_t$는 각각 그래디언트의 1차, 2차 모멘트 추정치, $\eta$는 학습률, $\lambda$는 가중치 감쇠 계수입니다.
코사인 학습률 스케줄은 다음과 같이 표현됩니다.
\[\eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})(1 + \cos(\frac{t}{T}\pi))\]상기 식에서 $\eta_t$는 시간 $t$에서의 학습률, $\eta_{min}$과 $\eta_{max}$는 각각 최소, 최대 학습률, $T$는 총 학습 스텝 수입니다.
2.4 효율적인 구현
LLaMA의 학습 속도를 향상시키기 위해 여러 최적화 기법을 적용했습니다.
- 인과적 다중 헤드 어텐션(causal multi-head attention)의 효율적 구현:
- xformers 라이브러리를 사용
- Rabe and Staats (2021)의 방법에서 영감을 받고 Dao et al. (2022)의 역전파 방식 사용
- 어텐션 가중치를 저장하지 않고, 인과성으로 인해 마스킹되는 key/query 스코어를 계산하지 않음
- 체크포인팅을 통한 역전파 시 재계산되는 활성화 함수 양 감소:
- 선형 레이어의 출력과 같이 계산 비용이 큰 활성화 값들을 저장
- PyTorch autograd 대신 트랜스포머 레이어의 역전파 함수를 수동으로 구현
- 모델 및 시퀀스 병렬화를 통한 메모리 사용량 감소 (Korthikanti et al., 2022)
- 활성화 함수 계산과 GPU 간 통신(all_reduce 연산으로 인한)을 최대한 겹치게 함
이런 최적화 기법들을 통해 65B 파라미터 모델 학습 시 2048개의 A100 GPU(80GB RAM)에서 GPU당 약 380 토큰/초의 처리 속도를 달성했습니다. 이는 1.4T 토큰으로 구성된 데이터셋에 대해 약 21일의 학습 시간이 소요됨을 의미합니다.
3. 주요 결과
LLaMA의 성능 평가는 20개의 벤치마크에서 zero-shot과 few-shot 태스크를 고려하여 진행되었습니다.
- Zero-shot: 태스크에 대한 텍스트 설명과 테스트 예제를 제공하고, 모델이 open-ended generation 또는 제안된 답변 랭킹을 수행
- Few-shot: 1-64개의 태스크 예제와 테스트 예제를 제공하고, 모델이 이를 입력으로 받아 답변 생성 또는 옵션 랭킹을 수행
LLaMA의 성능은 GPT-3, Gopher, Chinchilla, PaLM과 같은 비공개 언어 모델들과 OPT, GPT-J, GPT-Neo와 같은 오픈소스 모델들과 비교되었습니다.
3.1 상식 인퍼런스 (Common Sense Reasoning)
8개의 표준 상식 인퍼런스 벤치마크(BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-easy, ARC-challenge, OpenBookQA)에서 zero-shot 설정으로 평가를 진행했습니다.
- LLaMA-65B는 BoolQ를 제외한 모든 벤치마크에서 Chinchilla-70B를 능가
- LLaMA-65B는 BoolQ와 WinoGrande를 제외하고 PaLM-540B를 능가
- LLaMA-13B는 10배 작은 크기임에도 불구하고 대부분의 벤치마크에서 GPT-3를 능가
3.2 Closed-book 질의응답
Natural Questions와 TriviaQA 벤치마크에서 closed-book 설정으로 평가를 진행했습니다.
- LLaMA-65B는 zero-shot과 few-shot 설정 모두에서 최고 성능을 달성
- LLaMA-13B는 5-10배 작은 크기임에도 GPT-3와 Chinchilla와 경쟁력 있는 성능을 보임 (단일 V100 GPU에서 인퍼런스 가능)
3.3 독해력 (Reading Comprehension)
RACE 독해력 벤치마크에서 평가를 진행했습니다.
- LLaMA-65B는 PaLM-540B와 경쟁력 있는 성능을 보임
- LLaMA-13B는 GPT-3를 몇 퍼센트 포인트 앞섬
3.4 수학적 인퍼런스 (Mathematical reasoning)
MATH와 GSM8k 벤치마크에서 평가를 진행했습니다.
- LLaMA-65B는 수학 데이터에 대한 fine-tuning 없이도 GSM8k에서 Minerva-62B를 능가
3.5 코드 생성 (Code generation)
HumanEval과 MBPP 벤치마크에서 평가를 진행했습니다.
- LLaMA는 유사한 파라미터 수를 가진 다른 일반 모델들(LaMDA, PaLM)보다 우수한 성능을 보임
- LLaMA-13B 이상의 모델들은 HumanEval과 MBPP 모두에서 LaMDA-137B를 능가
- LLaMA-65B는 PaLM-62B를 능가 (더 오래 학습된 경우에도)
3.6 대규모 다중작업 언어 이해 (Massive Multitask Language Understanding, MMLU)
MMLU 벤치마크에서 5-shot 설정으로 평가를 진행했습니다.
- LLaMA-65B는 Chinchilla-70B와 PaLM-540B보다 평균적으로 몇 퍼센트 포인트 뒤쳐짐
- 이는 LLaMA의 Pre-training dataset에 책과 학술 논문의 양이 상대적으로 적었기 때문일 수 있음 (177GB vs 다른 모델들의 최대 2TB)
3.7 학습 중 성능 변화
학습 과정에서 몇 가지 질의응답 및 상식 벤치마크에 대한 성능을 추적했습니다.
- 대부분의 벤치마크에서 성능이 꾸준히 향상되며, 모델의 학습 퍼플렉서티와 상관관계를 보임
- SIQA와 WinoGrande는 예외적인 패턴을 보임 (특히 SIQA는 성능의 변동성이 크며, 이는 벤치마크의 신뢰성에 의문을 제기함)
결론적으로, LLaMA는 효율적인 학습 및 인퍼런스 전략을 통해 기존의 대규모 언어모델들과 비교하여 경쟁력 있는 성능을 달성했습니다. 특히 작은 크기의 모델(e.g., LLaMA-13B)이 훨씬 큰 모델들과 비교하여 우수한 성능을 보이는 점은 주목할 만합니다.
4. 명령어 파인튜닝 (Instruction Finetuning)
이 섹션에서는 소량의 명령어 데이터에 대한 파인튜닝이 MMLU(Massive Multitask Language Understanding) 성능을 빠르게 향상시킬 수 있음을 보여줍니다.
- 파인튜닝되지 않은 LLaMA-65B도 기본적인 명령을 따를 수 있지만, 소량의 파인튜닝으로 MMLU 성능과 명령 수행 능력이 더욱 향상됨
- Chung et al. (2022)의 프로토콜을 따라 LLaMA-I라는 명령어 모델을 학습
결과 (Table 10)
- LLaMA-I(65B)는 MMLU에서 68.9% 성능을 달성
- 이는 OPT-IML, Flan-PaLM 시리즈와 같은 기존의 중간 규모 명령어 파인튜닝 모델들을 능가함
- 그러나 GPT code-davinci-002의 77.4%에는 여전히 못 미치는 수준
5. 편향, 유해성 및 허위 정보
대규모 언어모델은 training dataset의 편향을 재생산하고 증폭시킬 수 있으며, 유해하거나 공격적인 콘텐츠를 생성할 수 있습니다. LLaMA의 training dataset에 웹 데이터가 큰 비중을 차지하므로, 이런 문제점들을 평가하는 것이 중요합니다.
5.1 RealToxicityPrompts
모델이 생성하는 유해 언어(모욕, 혐오 발언, 위협 등)를 평가
- 약 100k개의 프롬프트에 대해 모델이 문장을 완성
- PerspectiveAPI를 사용하여 자동으로 유해성 점수 평가 (0: 무해, 1: 유해)
결과 (Table 11)
- LLaMA의 점수는 기존 모델들(e.g., Chinchilla의 0.087)과 비슷한 수준
- 모델 크기가 커질수록 유해성이 증가하는 경향, 특히 “공손한” 프롬프트에서 두드러짐
- 이는 Zhang et al. (2022)의 관찰과 일치하지만, Hoffmann et al. (2022)의 결과와는 다름
5.2 CrowS-Pairs
9개 카테고리(성별, 종교, 인종/피부색, 성적 지향, 나이, 국적, 장애, 외모, 사회경제적 지위)에서의 편향 측정
- 각 예제는 고정관념과 반고정관념 문장으로 구성
- 0-shot 설정에서 두 문장의 퍼플렉서티를 측정하여 모델의 고정관념 선호도 평가
- 점수가 높을수록 더 큰 편향을 나타냄
결과 (Table 12)
- LLaMA-65B는 평균적으로 GPT-3와 OPT-175B보다 약간 나은 성능을 보임
- 종교 카테고리에서 특히 높은 편향 (+10%, OPT-175B 대비)
- 나이와 성별 카테고리에서도 상대적으로 높은 편향
5.3 WinoGender
성별 카테고리에서의 편향을 더 자세히 조사
- 상호참조 해결 데이터셋 사용
- 문장 내 “직업”, “참여자”, “대명사”의 상호참조 관계를 모델이 결정하는 능력 평가
- 성별에 따른 성능 차이를 관찰하여 직업과 관련된 사회적 편향 파악
결과 (Table 13)
- “their/them/someone” 대명사에 대한 성능이 “her/her/she”와 “his/him/he”보다 우수
- 이는 성별 편향의 징후로 해석됨
- “gotcha” 케이스(대명사가 직업의 다수 성별과 일치하지 않는 경우)에서 성능 저하 관찰
- 이는 모델이 성별과 직업에 관한 사회적 편향을 포착했음을 시사
5.4 TruthfulQA
모델의 진실성(허위 정보나 거짓 주장 생성 위험) 평가
- 38개 카테고리의 다양한 스타일의 질문으로 구성
- 실제 세계에 대한 “문자 그대로의 진실”을 기준으로 평가
결과 (Table 14)
- LLaMA 모델들은 GPT-3보다 높은 점수를 기록 (진실성 및 진실성*정보성 측면에서)
- 그러나 여전히 정답률이 낮아, 모델이 부정확한 답변을 생성할 가능성이 있음을 시사
LLaMA는 기존 모델들과 비교하여 편향, 유해성, 허위 정보 생성 측면에서 약간 나은 성능을 보이지만, 여전히 상당한 문제점들이 존재합니다. 특히 모델 크기가 커질수록 일부 문제가 악화되는 경향이 관찰되어, 향후 연구에서 이를 해결하기 위한 노력이 필요할 것으로 보입니다. 또한, 이런 평가들이 모델과 관련된 모든 위험을 완전히 이해하기에는 충분하지 않다는 점을 유의해야 합니다.
6. 탄소 발자국
LLaMA 모델 학습 과정에서 막대한 양의 에너지가 소비되었으며, 이는 상당한 양의 이산화탄소 배출로 이어졌습니다. 연구진은 최근 문헌을 따라 총 에너지 소비량과 그로 인한 탄소 발자국을 분석했습니다.
- Wu et al. (2022)의 공식을 사용하여 모델 학습에 필요한 와트시(Wh)와 탄소 배출량(tCO2eq) 추정
- 와트시 계산 공식: Wh = GPU-h × (GPU 전력 소비) × PUE
- 탄소 배출량은 데이터 센터의 위치에 따라 달라짐 (e.g., BLOOM 27 tCO2eq, OPT 82 tCO2eq)
- 공정한 비교를 위해 미국 평균 탄소 강도 계수 0.385 kg CO2eq/KWh 사용
- 탄소 배출량 계산 공식: tCO2eq = MWh × 0.385
LLaMA 모델 개발의 에너지 소비 및 탄소 배출 추정
- 2048 A100-80GB GPU를 약 5개월 동안 사용
- 총 에너지 소비량: 약 2,638 MWh
- 총 탄소 배출량: 약 1,015 tCO2eq
모델별 세부 내역 (Table 15)
- LLaMA-7B: 36 MWh, 14 tCO2eq
- LLaMA-13B: 59 MWh, 23 tCO2eq
- LLaMA-33B: 233 MWh, 90 tCO2eq
- LLaMA-65B: 449 MWh, 173 tCO2eq
비교
- OPT-175B: 356 MWh, 137 tCO2eq
- BLOOM-175B: 475 MWh, 183 tCO2eq
연구진은 이런 모델들을 공개함으로써 향후 탄소 배출을 줄일 수 있기를 희망합니다. 이미 학습된 모델을 재사용하고, 일부 작은 모델들은 단일 GPU에서도 실행 가능하기 때문입니다.
7. 관련 연구
- 언어 모델의 정의와 중요성
- 단어, 토큰, 문자 시퀀스의 확률 분포
- 자연어 처리의 핵심 문제로 간주됨
- 인공지능 진보를 측정하는 벤치마크로 제안됨
- 아키텍처 발전
- n-gram 통계 기반 모델
- 신경망 모델: 피드포워드, RNN, LSTM
- 트랜스포머 네트워크: self-attention 메커니즘 기반, 장거리 의존성 포착에 우수
- 스케일링
- 모델 크기와 데이터셋 크기의 지속적인 확장
- 주요 모델들: BERT, GPT-2, MegatronLM, T5, GPT-3 등
- 스케일링의 영향 연구: 성능과 모델/데이터셋 크기 간의 멱법칙 관계 발견
- 대규모 언어모델
- GPT-3 (175B 파라미터) 이후 다양한 대규모 모델 등장
- Jurassic-1, Megatron-Turing NLG, Gopher, Chinchilla, PaLM, OPT, GLM 등
- 스케일링 법칙 연구
- Hestness et al. (2017), Rosenfeld et al. (2019): 딥러닝 모델의 스케일링 영향 연구
- Kaplan et al. (2020): 트랜스포머 기반 언어 모델의 멱법칙 도출
- Hoffmann et al. (2022): 데이터셋 스케일링 시 학습률 스케줄 조정
- Wei et al. (2022): 대규모 언어모델의 능력에 대한 스케일링 효과 연구
본문
1 Introduction
Large Language Models (LLMs) trained on massive corpora of texts have shown their ability to perform new tasks from textual instructions or from a few examples (Brown et al., 2020). These few-shot properties first appeared when scaling models to a sufficient size (Kaplan et al., 2020), resulting in a line of work that focuses on further scaling these models (Chowdhery et al., 2022; Rae et al., 2021). These efforts are based on the assumption that more parameters will lead to better performance. However, recent work from Hoffmann et al. (2022) shows that, for a given compute budget, the best performances are not achieved by the largest models, but by smaller models trained on more data. The objective of the scaling laws from Hoffmann et al. (2022) is to determine how to best scale the dataset and model sizes for a particular training compute budget. However, this objective disregards the inference budget, which becomes critical when serving a language model at scale. In this context, given a target level of performance, the preferred model is not the fastest to train but the fastest at inference, and although it may be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference. For instance, although Hoffmann et al. (2022) recommends training a 10B model on 200B tokens, we find that the performance of a 7B model continues to improve even after 1T tokens. The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used. The resulting models, called LLaMA, range from 7B to 65B parameters with competitive performance compared to the best existing LLMs. For instance, LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller. We believe that this model will help democratize the access and study of LLMs since it can be run on a single GPU. At the higher end of the scale, our 65B-parameter model is also competitive with the best large language models such as Chinchilla or PaLM-540B. Unlike Chinchilla, PaLM, or GPT-3, we only use publicly available data, making our work compatible with open-sourcing, while most existing models rely on data which is either not publicly available or undocumented (e.g., “Books–2TB” or “Social media conversations”). There exist some exceptions, notably OPT (Zhang et al., 2022), GPT-NeoX (Black et al., 2022), BLOOM (Scao et al., 2022), and GLM (Zeng et al., 2022), but none that are competitive with PaLM-62B or Chinchilla. In the rest of this paper, we present an overview of the modifications we made to the transformer architecture (Vaswani et al., 2017), as well as our training method. We then report the performance of our models and compare with other LLMs on a set of standard benchmarks. Finally, we expose some of the biases and toxicity encoded in our models, using some of the most recent benchmarks from the responsible AI community.
2 Approach
Our training approach is similar to the methods described in previous work (Brown et al., 2020; Chowdhery et al., 2022) and is inspired by the Chinchilla scaling laws (Hoffmann et al., 2022). We train large transformers on a large quantity of textual data using a standard optimizer.
2.1 Pre-training Data
Our training dataset is a mixture of several sources, reported in Table 1, that cover a diverse set of domains. For the most part, we use data sources that have been leveraged to train other LLMs, with the restriction of only using data that is publicly available and compatible with open-sourcing. This leads to the following mixture of data and the percentage they represent in the training set:
- English Common Crawl [67%].
- C4 [15%].
- Github [4.5%].
- Wikipedia [4.5%].
- Gutenberg and Books3 [4.5%].
- ArXiv [2.5%].
-
StackExchange [2%].
- Tokenizer We tokenize the data with the byte pair encoding (BPE) algorithm (Sennrich et al., 2015), using the implementation from SentencePiece (Kudo and Richardson, 2018). Notably, we split all numbers into individual digits and fall back to bytes to decompose unknown UTF-8 characters. Overall, our entire training dataset contains roughly 1.4T tokens after tokenization. For most of our training data, each token is used only once during training, with the exception of the Wikipedia and Books domains, over which we perform approximately two epochs.
2.2 Architecture
Following recent work on large language models, our network is based on the transformer architecture (Vaswani et al., 2017). We leverage various improvements that were subsequently proposed and used in different models such as PaLM. Here are the main differences with the original architecture, and where we found the inspiration for this change (in brackets):
- Pre-normalization [GPT3]: To improve the training stability, we normalize the input of each transformer sub-layer, instead of normalizing the output. We use the RMSNorm normalizing function, introduced by Zhang and Sennrich (2019).
- SwiGLU activation function [PaLM]: We replace the ReLU non-linearity by the SwiGLU activation function, introduced by Shazeer (2020) to improve performance. We use a dimension of 234d instead of 4d as in PaLM.
- Rotary Embeddings [GPTNeo]: We remove the absolute positional embeddings and instead add rotary positional embeddings (RoPE), introduced by Su et al. (2021), at each layer of the network.
The details of the hyper-parameters for our different models are given in Table 2.
2.3 Optimizer
Our models are trained using the AdamW optimizer (Loshchilov and Hutter, 2017), with the following hyper-parameters: β1=0.9, β2=0.95. We use a cosine learning rate schedule, such that the final learning rate is equal to 10% of the maximal learning rate. We use a weight decay of 0.1 and gradient clipping of 1.0. We use 2,000 warm-up steps and vary the learning rate and batch size with the size of the model (see Table 2 for details).
2.4 Efficient Implementation
We make several optimizations to improve the training speed of our models. First, we use an efficient implementation of the causal multi-head attention to reduce memory usage and runtime. This implementation, available in the xformers library, is inspired by Rabe and Staats (2021) and uses the backward method from Dao et al. (2022). This is achieved by not storing the attention weights and not computing the key/query scores that are masked due to the causal nature of the language modeling task.
To further improve training efficiency, we reduce the amount of activations that are recomputed during the backward pass with checkpointing. More precisely, we save the activations that are expensive to compute, such as the outputs of linear layers. This is achieved by manually implementing the backward function for the transformer layers, instead of relying on the PyTorch autograd.
To fully benefit from this optimization, we need to reduce the memory usage of the model by using model and sequence parallelism, as described by Korthikanti et al. (2022). Moreover, we also overlap the computation of activations and the communication between GPUs over the network (due to all_reduce operations) as much as possible.
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
3 Main Results
Following previous work (Brown et al., 2020), we consider zero-shot and few-shot tasks and report results on a total of 20 benchmarks:
- Zero-shot: We provide a textual description of the task and a test example. The model either provides an answer using open-ended generation or ranks the proposed answers.
- Few-shot: We provide a few examples of the task (between 1 and 64) and a test example. The model takes this text as input and generates the answer or ranks different options.
We compare LLaMA with other foundation models, namely the non-publicly available language models GPT-3 (Brown et al., 2020), Gopher (Rae et al., 2021), Chinchilla (Hoffmann et al., 2022), and PaLM (Chowdhery et al., 2022), as well as the open-sourced OPT models (Zhang et al., 2022), GPT-J (Wang and Komatsuzaki, 2021), and GPT-Neo (Black et al., 2022). In Section 4, we also briefly compare LLaMA with instruction-tuned models such as OPT-IML (Iyer et al., 2022) and Flan-PaLM (Chung et al., 2022). We evaluate LLaMA on free-form generation tasks and multiple-choice tasks.
In the multiple-choice tasks, the objective is to select the most appropriate completion among a set of given options, based on a provided context. We select the completion with the highest likelihood given the provided context, using likelihood normalized by the number of characters in the completion, except for certain datasets (OpenBookQA, BoolQ), for which we follow Brown et al. (2020) and select a completion based on the likelihood normalized by the likelihood of the completion given "Answer:" as context: P(completion|context)/P(completion| "Answer:").
3.1 Common Sense Reasoning
We consider eight standard common sense reasoning benchmarks: BoolQ (Clark et al., 2019), PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019), WinoGrande (Sakaguchi et al., 2021), ARC easy and challenge (Clark et al., 2018), and OpenBookQA (Mihaylov et al., 2018). These datasets include Cloze and Winograd-style tasks, as well as multiple-choice question answering. We evaluate in the zero-shot setting as done in the language modeling community. In Table 3, we compare with existing models of various sizes and report numbers from the corresponding papers. First, LLaMA-65B outperforms Chinchilla-70B on all reported benchmarks but BoolQ. Similarly, this model surpasses PaLM-540B everywhere but on BoolQ and WinoGrande. LLaMA-13B model also outperforms GPT-3 on most benchmarks despite being 10× smaller.
3.2 Closed-book Question Answering
We compare LLaMA to existing large language models on two closed-book question answering benchmarks: Natural Questions (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017). For both benchmarks, we report exact match performance in a closed book setting, i.e., where the models do not have access to documents that contain evidence to answer the question. In Table 4, we report performance on Natural Questions, and in Table 5, we report on TriviaQA. On both benchmarks, LLaMA-65B achieves state-of-the-art performance in the zero-shot and few-shot settings. More importantly, the LLaMA-13B is also competitive on these benchmarks with GPT-3 and Chinchilla, despite being 5-10× smaller. This model runs on a single V100 GPU during inference.
3.3 Reading Comprehension
We evaluate our models on the RACE reading comprehension benchmark (Lai et al., 2017). This dataset was collected from English reading comprehension exams designed for middle and high school Chinese students. We follow the evaluation setup from Brown et al. (2020) and report results in Table 6. On these benchmarks, LLaMA-65B is competitive with PaLM-540B, and LLaMA-13B outperforms GPT-3 by a few percent.
3.4 Mathematical Reasoning
We evaluate our models on two mathematical reasoning benchmarks: MATH (Hendrycks et al., 2021) and GSM8k (Cobbe et al., 2021). MATH is a dataset of 12K middle school and high school mathematics problems written in LaTeX. GSM8k is a set of middle school mathematical problems. In Table 7, we compare with PaLM and Minerva (Lewkowycz et al., 2022). Minerva is a series of PaLM models fine-tuned on 38.5B tokens extracted from ArXiv and MathWebPages, while neither PaLM nor LLaMA are fine-tuned on mathematical data. The numbers for PaLM and Minerva are taken from Lewkowycz et al. (2022), and we compare with and without maj1@k. maj1@k denotes evaluations where we generate k samples for each problem and perform a majority voting (Wang et al., 2022). On GSM8k, we observe that LLaMA-65B outperforms Minerva-62B, although it has not been fine-tuned on mathematical data.
3.5 Code Generation
We evaluate the ability of our models to write code from a natural language description on two benchmarks: HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021). For both tasks, the model receives a description of the program in a few sentences, as well as a few input-output examples. In HumanEval, it also receives a function signature, and the prompt is formatted as natural code with the textual description and tests in a docstring. The model needs to generate a Python program that fits the description and satisfies the test cases. In Table 8, we compare the pass@1 scores of our models with existing language models that have not been fine-tuned on code, namely PaLM and LaMDA (Thoppilan et al., 2022). PaLM and LLaMA were trained on datasets that contain a similar number of code tokens. As shown in Table 8, for a similar number of parameters, LLaMA outperforms other general models such as LaMDA and PaLM, which are not trained or fine-tuned specifically for code. LLaMA with 13B parameters and more outperforms LaMDA-137B on both HumanEval and MBPP. LLaMA-65B also outperforms PaLM-62B, even when it is trained longer. The pass@1 results reported in this table were obtained by sampling with temperature 0.1. The pass@100 and pass@80 metrics were obtained with temperature 0.8. We use the same method as Chen et al. (2021) to obtain unbiased estimates of the pass@k. It is possible to improve the performance on code by fine-tuning on code-specific tokens. For instance, PaLM-Coder (Chowdhery et al., 2022) increases the pass@1 score of PaLM on HumanEval from 26.2% for PaLM to 36%. Other models trained specifically for code also perform better than general models on these tasks (Chen et al., 2021; Nijkamp et al., 2022; Fried et al., 2022). Fine-tuning on code tokens is beyond the scope of this paper.
3.6 Massive Multitask Language Understanding
The massive multitask language understanding benchmark, or MMLU, introduced by Hendrycks et al. (2020) consists of multiple-choice questions covering various domains of knowledge, including humanities, STEM, and social sciences. We evaluate our models in the 5-shot setting, using the examples provided by the benchmark, and report results in Table 9. On this benchmark, we observe that the LLaMA-65B is behind both Chinchilla-70B and PaLM-540B by a few percent on average, and across most domains. A potential explanation is that we have used a limited amount of books and academic papers in our pre-training data, i.e., ArXiv, Gutenberg, and Books3, that sums up to only 177GB, while these models were trained on up to 2TB of books. This large quantity of books used by Gopher, Chinchilla, and PaLM may also explain why Gopher outperforms GPT-3 on this benchmark, while it is comparable on other benchmarks.
3.7 Evolution of Performance During Training
During training, we tracked the performance of our models on a few question answering and common sense benchmarks, and report them in Figure 2. On most benchmarks, the performance improves steadily and correlates with the training perplexity of the model (see Figure 1). The exceptions are SIQA and WinoGrande. Most notably, on SIQA, we observe a lot of variance in performance, which may indicate that this benchmark is not reliable. On WinoGrande, the performance does not correlate as well with training perplexity: the LLaMA-33B and LLaMA-65B have similar performance during training.
4 Instruction Fine-tuning
In this section, we show that briefly fine-tuning on instructions data rapidly leads to improvements on MMLU. Although the non-finetuned version of LLaMA-65B is already able to follow basic instructions, we observe that a very small amount of fine-tuning improves the performance on MMLU and further improves the ability of the model to follow instructions. Since this is not the focus of this paper, we only conducted a single experiment following the same protocol as Chung et al. (2022) to train an instruct model, LLaMA-I. In Table 10, we report the results of our instruct model LLaMA-I on MMLU and compare with existing instruction fine-tuned models of moderate sizes, namely, OPT-IML (Iyer et al., 2022) and the Flan-PaLM series (Chung et al., 2022). All the reported numbers are from the corresponding papers. Despite the simplicity of the instruction fine-tuning approach used here, we reach 68.9% on MMLU. LLaMA-I(65B) outperforms on MMLU existing instruction fine-tuned models of moderate sizes but is still far from the state-of-the-art, that is 77.4 for GPT code-davinci-002 on MMLU (numbers taken from Iyer et al. (2022)). The details of the performance on MMLU on the 57 tasks can be found in Table 16 of the appendix.
5 Bias, Toxicity, and Misinformation
Large language models have been shown to reproduce and amplify biases that are existing in the training data (Sheng et al., 2019; Kurita et al., 2019) and to generate toxic or offensive content (Gehman et al., 2020). As our training dataset contains a large proportion of data from the Web, we believe that it is crucial to determine the potential for our models to generate such content. To understand the potential harm of LLaMA-65B, we evaluate on different benchmarks that measure toxic content production and stereotypes detection.
5.1 Real Toxicity Prompts
Language models can generate toxic language, e.g., insults, hate speech, or threats. There is a very large range of toxic content that a model can generate, making a thorough evaluation challenging. Several recent works (Zhang et al., 2022; Hoffmann et al., 2022) have considered the Real Toxicity Prompts benchmark (Gehman et al., 2020) as an indicator of how toxic their model is. Real Toxicity Prompts consist of about 100k prompts that the model must complete; then a toxicity score is automatically evaluated by making a request to PerspectiveAPI. We do not have control over the pipeline used by the third-party PerspectiveAPI, making comparison with previous models difficult.
For each of the 100k prompts, we greedily generate with our models and measure their toxicity score. The score per prompt ranges from 0 (non-toxic) to 1 (toxic). In Table 11, we report our averaged score on basic and respectful prompt categories of Real Toxicity Prompts. These scores are “comparable” with what we observe in the literature (e.g., 0.087 for Chinchilla), but the methodologies differ between these work and ours (in terms of sampling strategy, number of prompts, and time of API). We observe that toxicity increases with the size of the model, especially for Respectful prompts. This was also observed in previous work (Zhang et al., 2022), with the notable exception of Hoffmann et al. (2022) where they do not see a difference between Chinchilla and Gopher, despite different sizes. This could be explained by the fact that the larger model, Gopher, has worse performance than Chinchilla, suggesting that the relation between toxicity and model size may only apply within a model family.
5.2 CrowS-Pairs
We evaluate the biases in our model on the CrowS-Pairs (Nangia et al., 2020). This dataset allows us to measure biases in 9 categories: gender, religion, race/color, sexual orientation, age, nationality, disability, physical appearance, and socioeconomic status. Each example is composed of a stereotype and an anti-stereotype, we measure the model preference for the stereotypical sentence using the perplexity of both sentences in a zero-shot setting. Higher scores thus indicate higher bias. We compare with GPT-3 and OPT-175B in Table 12. LLaMA compares slightly favorably to both models on average. Our model is particularly biased in the religion category (+10% compared to OPT-175B), followed by age and gender. We expect these biases to come from Common Crawl despite multiple filtering steps.
5.3 WinoGender
To further investigate the biases of our model on the gender category, we look at the WinoGender benchmark (Rudinger et al., 2018), a co-reference resolution dataset. WinoGender is made of Winograd schemas, and biases are evaluated by determining if a model co-reference resolution performance is impacted by the gender of the pronoun. More precisely, each sentence has three mentions: an “occupation,” a “participant,” and a “pronoun” where the pronoun is co-referencing either the occupation or participant. We prompt the model to determine the co-reference relation and measure if it does so correctly according to the context of the sentence. The goal is to reveal if societal biases associated with occupations have been captured by the model. For example, a sentence in the WinoGender dataset is “The nurse notified the patient that his shift would be ending in an hour.”, which is followed by ‘His’ refers to. We then compare the perplexity of the continuations “the nurse” and “the patient” to perform co-reference resolution with the model. We evaluate the performance when using 3 pronouns: “her/her/she”, “his/him/he”, and “their/them/someone” (the different choices corresponding to the grammatical function of the pronoun). In Table 13, we report the co-reference scores for the three different pronouns contained in the dataset. We observe that our model is significantly better at performing co-reference resolution for the “their/them/someone” pronouns than for the “her/her/she” and “his/him/he” pronouns. A similar observation was made in previous work (Rae et al., 2021; Hoffmann et al., 2022), and is likely indicative of gender bias. Indeed, in the case of the “her/her/she” and “his/him/he” pronouns, the model is probably using the majority gender of the occupation to perform co-reference resolution, instead of using the evidence of the sentence.
To further investigate this hypothesis, we look at the set of “gotcha” cases for the “her/her/she” and “his/him/he” pronouns in the WinoGender dataset. These cases correspond to sentences in which the pronoun does not match the majority gender of the occupation, and the occupation is the correct answer. In Table 13, we observe that our model, LLaMA-65B, makes more errors on the gotcha examples, clearly showing that it captures societal biases related to gender and occupation. The drop of performance exists for “her/her/she” and “his/him/he” pronouns, which is indicative of biases regardless of gender.
5.4 TruthfulQA
TruthfulQA (Lin et al., 2021) aims to measure the truthfulness of a model, i.e., its ability to identify when a claim is true. Lin et al. (2021) consider the definition of “true” in the sense of “literal truth about the real world,” and not claims that are only true in the context of a belief system or tradition. This benchmark can evaluate the risks of a model to generate misinformation or false claims. The questions are written in diverse styles, cover 38 categories, and are designed to be adversarial. In Table 14, we report the performance of our models on both questions to measure truthful models and the intersection of truthful and informative. Compared to GPT-3, our models score higher in both categories, but the rate of correct answers is still low, showing that our model is likely to hallucinate incorrect answers.
6. Carbon Footprint
The training of our models has consumed a massive quantity of energy, responsible for the emission of carbon dioxide. We follow the recent literature on the subject and break down both the total energy consumption and the resulting carbon footprint in Table 15. We follow a formula for Wu et al. (2022) to estimate the Watt-hour, Wh, needed to train a model, as well as the tons of carbon emissions, tCO2eq. For the Wh, we use the formula:
\[Wh = GPU-h × (GPU power consumption) × PUE\]where we set the Power Usage Effectiveness (PUE) at 1.1. The resulting carbon emission depends on the location of the data center used to train the network. For instance, BLOOM uses a grid that emits 0.057kgCO2eq/KWh leading to 27tCO2eq, and OPT a grid that emits 0.231kgCO2eq/KWh, leading to 82tCO2eq. In this study, we are interested in comparing the cost in carbon emission of training of these models if they were trained in the same data center. Hence, we do not take the location of the data center into consideration, and use, instead, the US national average carbon intensity factor of 0.385kgCO2eq/KWh. This leads to the following formula for the tons of carbon emissions:
\[tCO2eq = MWh × 0.385\]We apply the same formula to OPT and BLOOM for fair comparison. For OPT, we assume training required 34 days on 992A100-80B (see their logs4). Finally, we estimate that we used 2048A100-80GB for a period of approximately 5 months to develop our models. This means that developing these models would have cost around 2,638 MWh under our assumptions, and a total emission of 1,015 tCO2eq. We hope that releasing these models will help to reduce future carbon emissions since the training is already done, and some of the models are relatively small and can be run on a single GPU.