Automatic Instruction Evolving
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-02
Automatic Instruction Evolving for Large Language Models
- url: https://arxiv.org/abs/2406.00770
- pdf: https://arxiv.org/pdf/2406.00770
- html: https://arxiv.org/html/2406.00770v1
- abstract: Fine-tuning large pre-trained language models with Evol-Instruct has achieved encouraging results across a wide range of tasks. However, designing effective evolving methods for instruction evolution requires substantial human expertise. This paper proposes Auto Evol-Instruct, an end-to-end framework that evolves instruction datasets using large language models without any human effort. The framework automatically analyzes and summarizes suitable evolutionary strategies for the given instruction data and iteratively improves the evolving method based on issues exposed during the instruction evolution process. Our extensive experiments demonstrate that the best method optimized by Auto Evol-Instruct outperforms human-designed methods on various benchmarks, including MT-Bench, AlpacaEval, GSM8K, and HumanEval.
Contents
TL;DR
- 수동으로 설계된 Evol-Instruct 방법의 제한점을 극복하기 위한 자동화된 프레임워크 개발
- 초기 진화(evolving) 방법 설계 후, LLM을 통해 지속적으로 최적화하여 자동화된 진화 방법을 도출
- 자동화된 방법이 수동 방법을 능가하며, 다양한 작업에서 우수한 성능을 보임
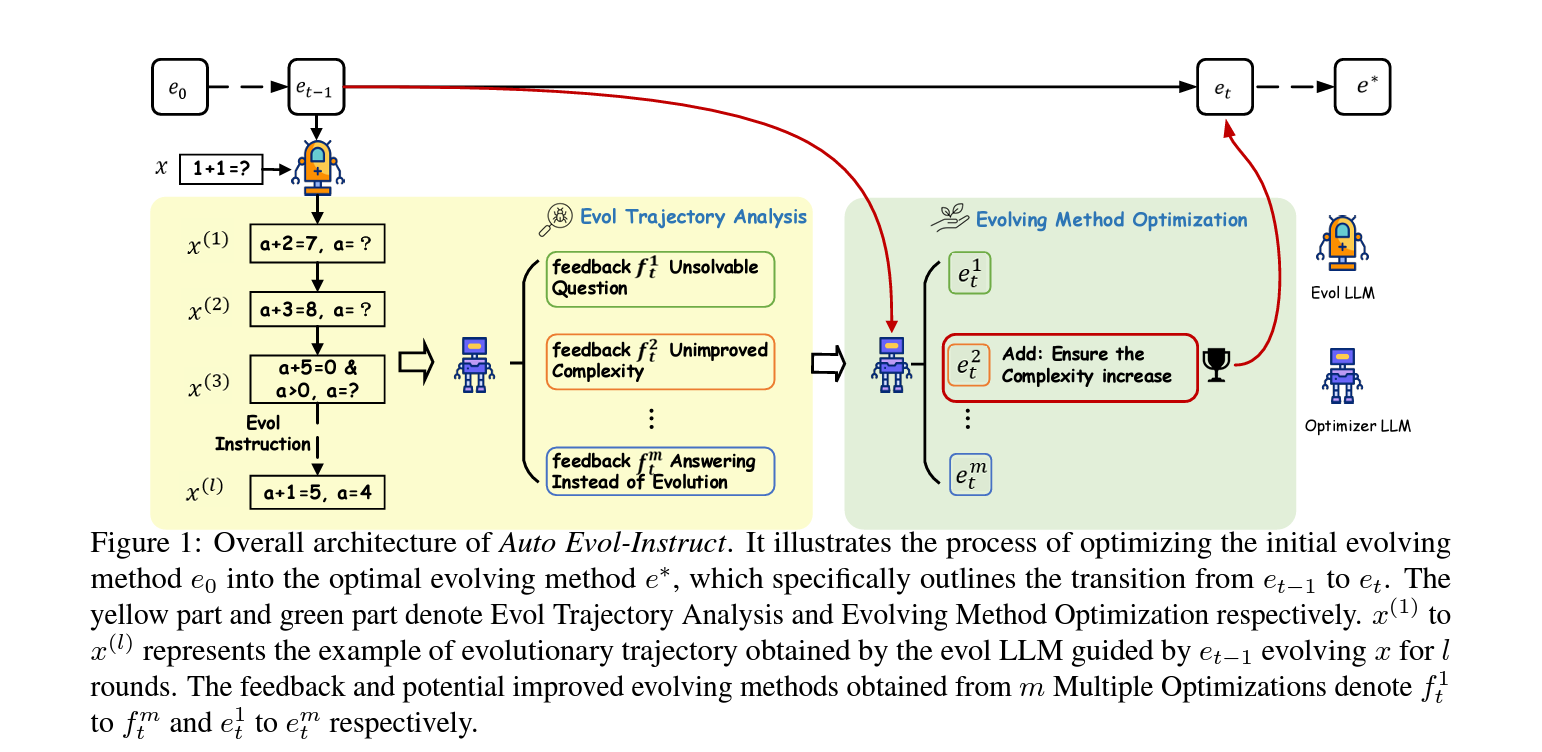

1. 서론
대규모 언어모델(LLM)을 정밀하게 튜닝하여 지시를 따르게 하는 것은 잠재력을 극대화하는 데 중요합니다(Ouyang et al., 2022; Touvron et al., 2023b). ShareGPT, OpenAssistant, LIMA와 같은 고품질 데이터셋은 지시 튜닝의 성능을 크게 향상시켰습니다(Chiang et al., 2023; Köpf et al., 2023; Zhou et al., 2023). 그러나, 이런 데이터셋을 제작하는 것은 확장이 어렵고 품질의 상한선이 존재합니다. 이를 극복하기 위해 Xu et al. (2023), Yu et al. (2023), Liu et al. (2023b)은 기존 데이터셋의 품질 상한을 돌파하는 방법을 모색하고 있습니다. Evol-Instruct(Xu et al., 2023)는 고품질 데이터를 출발점으로 하여 LLM을 사용해 데이터를 반복적으로 개선하는 방법으로, 지시 따라하기, 코드 생성, 수학적 인퍼런스 등 다양한 공개 벤치마크에서 우수한 성능을 보였습니다(Zheng et al., 2023; Li et al., 2023; Luo et al., 2023a; Cobbe et al., 2021).
Evol-Instruct는 향상된 성능을 보이지만, 새로운 작업에 대해 방법을 재설계해야 하는 문제점이 있습니다. 이를 해결하기 위해 Evol-Instruct의 자동화를 제안합니다. 이를 위해서는 다음과 같은 어려움이 있습니다. (1) 주어진 작업에 대해 지시를 더 복잡하게 만드는 방법을 자동으로 설계 (2) 진화 실패를 방지하여 지시 진화 과정을 올바르게 유지.
2. 배경
2.1 Evol-Instruct
Evol-Instruct는 지시 데이터셋을 정제하여 그 복잡성과 다양성을 향상시키는 방법입니다. 휴먼이 설계한 진화 방법 $e$를 사용하여 원래의 지시 데이터셋 $X$를 개선된 데이터셋 $X_e$로 변환합니다. 목표는 지시 튜닝 후 특정 능력에서 $X_e$가 $X$보다 더 나은 성능 $Q(X_e)$을 발휘하도록 하는 것입니다.
2.2 문제 정의
Evol-Instruct의 성능은 뛰어나지만, 높은 전문성과 제한된 범위로 인해 널리 사용되기 어렵습니다. 자동화된 프레임워크를 개발하여 최적의 지시 진화 방법 $e^*$을 찾고자 합니다.
\[e^* = \arg \max_e Q(X_e).\]이 프레임워크는 지시 튜닝 후 최고 성능을 발휘하는 진화 방법 $e^*$을 자동으로 찾아냅니다.
3. Auto Evol-Instruct
Auto Evol-Instruct는 휴먼의 개입 없이 지시 데이터를 개선하는 완전 자동화 프레임워크입니다. 주요 발전 사항은 다음과 같습니다.
- (1) 지시 진화를 위한 진화 방법을 자동으로 설계하여 다양한 작업에 쉽게 적응
- (2) 휴먼 전문가가 설계한 방법을 능가하는 진화 방법을 개발하여 실패를 최소화
3.1 초기 진화 방법 설계
Evol-Instruct가 보편적으로 적용되지 않는 이유는 각 도메인마다 지시를 복잡하게 만드는 방법이 다르기 때문입니다. Auto Evol-Instruct는 이런 방법을 LLM에 위임하여 자동으로 설계합니다. 먼저 evol LLM이 지시를 읽고 이를 복잡하게 만드는 방법을 나열합니다. 그런 다음, 이 방법들을 기반으로 종합적인 계획을 세워 진화된 지시를 생성합니다.
3.2 진화 경로 분석
주로 optimizer LLM을 사용하여 진화 과정에서 발생하는 문제를 식별하고 최적화를 위한 피드백을 제공합니다. 진화 경로에서 $X_t$에서 $X_t(l)$까지의 각 단계를 분석하여 문제를 식별하고 피드백 $f_t$를 생성합니다.
3.3 진화 방법 최적화
optimizer LLM은 피드백 $f_t$를 기반으로 진화 방법 $e_t-1$을 최적화합니다. 이 과정에서 여러 번의 분석 및 최적화를 통해 $m$개의 잠재적인 진화 방법을 생성하고, 가장 낮은 실패율을 보이는 방법을 선택하여 다음 단계의 진화 방법으로 사용합니다.
3.4 진화된 데이터로 지시 튜닝
Auto Evol-Instruct는 최적의 진화 방법 $e^*$을 도출하여 전체 지시 데이터셋의 복잡성과 다양성을 크게 향상시킵니다. 이 데이터셋을 사용하여 기본 LLM을 튜닝하여 모델의 범위를 넓힙니다.
4. 실험
이 섹션에서는 Auto Evol-Instruct의 효과를 상세히 분석합니다. 실험 설정 개요를 설명하고, 지시 따라하기, 수학적 인퍼런스, 코드 생성에서 방법의 효과를 테스트합니다.
- Evol-Instruct의 제한점 극복을 위한 자동화된 방법 제안.
- 초기 진화 방법을 설계하고 LLM을 통해 지속적으로 최적화하여 최적의 방법 도출.
- 자동화된 방법이 수동 방법을 능가하며 다양한 작업에서 우수한 성능 발휘.
4.1 실험 설정
실험 설정에는 지시 튜닝을 위한 다양한 크기의 사전 훈련된 모델, 진화 LLM 및 최적화 LLM의 구성 등이 포함됩니다. 자세한 내용은 Appendix D와 Appendix E를 참조하세요.
4.2 평가 결과
지시 따라하기
MT-Bench와 AlpacaEval을 사용하여 지시 따라하기 성능을 평가합니다. MT-Bench는 다양한 도메인에서 다중 턴 대화를 통해 모델을 테스트하고, AlpacaEval은 AlpacaFarm을 기반으로 자동 평가합니다. Table 2는 본 논문의 방법이 다양한 모델 규모에서 성능을 크게 향상시키는 것을 보여줍니다. 작은 모델의 경우, 방법은 Seed Data에 비해 MT-Bench에서 약 0.63만큼 성능이 향상됩니다. 큰 모델의 경우에도 0.44만큼 성능이 향상됩니다. Mixtral-8x7B에서 10K 데이터만을 사용하여 파인튜닝했음에도 불구하고, 방법은 더 많은 데이터를 사용하고 더 큰 모델에서 훈련된 오픈 소스 모델의 성능을 능가하거나 일치하며, MT-Bench와 AlpacaEval에서 Tulu-v2-dpo와 비교할 만한 성능을 달성합니다.
수학적 인퍼런스
GSM8K 벤치마크를 사용하여 수학적 인퍼런스 능력을 평가합니다. GSM8K는 복잡한 대학원 수준의 수학 문제로 구성되어 있으며, 7,473개의 훈련 샘플과 1,319개의 테스트 샘플이 포함되어 있습니다. 0-shot 테스트 접근 방식을 사용하고, 테스트 정확도를 메트릭으로 사용합니다. Table 2는 Auto Evol-Instruct가 수학적 인퍼런스를 크게 개선한 것을 보여줍니다. 예를 들어, 방법은 Mistral-7B에서 Seed Data에 비해 13.84만큼 성능을 향상시켰습니다. 동시에, 방법은 최소한의 지시 데이터(7K)만을 사용하고도 Mixtral-8x7B에서 파인튜닝 후 GPT-3.5-turbo를 능가할 수 있습니다. 이는 방법이 기존 수학 데이터의 품질 상한선을 크게 높일 수 있음을 나타냅니다.
코드 생성
HumanEval을 사용하여 코드 작성 능력을 테스트합니다. HumanEval은 164개의 고유한 프로그래밍 챌린지로 구성되어 있으며, pass@1을 메트릭으로 사용합니다. Table 2는 방법이 모델의 능력을 효과적으로 향상시키는 것을 보여줍니다. 다양한 모델 크기에서 Evol-Instruct와 비교하여 방법이 크게 향상된 성능을 보였습니다. 예를 들어, 33B 규모에서 Evol-Instruct는 약간의 개선만을 보여주었지만, 방법은 Seed Data에 비해 5.4만큼 성능이 향상되었습니다. 결과는 같은 기본 모델을 사용하되 더 많은 규모(약 2B 토큰)로 지시 튜닝된 DeepSeek-Coder-Instruct-33B와 비교할 때도 경쟁력이 있습니다.
| Model | Size | MT-Bench | AlpacaEval (%) | GSM8K (%) | HumanEval (%) |
|---|---|---|---|---|---|
| Seed Data (small) | 6.88 | 84.08 | 56.90 | 57.90 | |
| Evol-Instruct (small) | 6.80 | (-0.08) | 86.67 (+2.59) | 63.15 (+6.25) | 61.59 (+3.69) |
| Auto Evol-Instruct (small) | 7.51 | (+0.63) | 84.41 (+0.33) | 70.74 (+13.84) | 65.85 (+7.95) |
| Seed Data (large) | 7.65 | 87.98 | 70.60 | 72.00 | |
| Evol-Instruct (large) | 7.76 | (+0.11) | 89.50 (+1.52) | 79.15 (+8.55) | 73.20 (+1.20) |
| Auto Evol-Instruct (large) | 8.09 | (+0.44) | 91.37 (+3.39) | 82.49 (+11.89) | 77.40 (+5.40) |
5. 분석
5.1 초기 진화 방법의 효과
이 섹션에서는 Auto Evol-Instruct 프레임워크 내에서 초기 진화 방법의 중요성, 특히 다양한 능력에 대한 데이터 진화에 미치는 영향을 탐구합니다. Figure 3은 초기 진화 방법이 다양한 능력을 강화하는 데 있어서의 강력한 다재다능성을 강조하며, 프레임워크의 훌륭한 시작 진화 방법임을 입증합니다. 예를 들어, Evol Instruct와 비교했을 때 초기 진화 방법은 MT-Bench 점수를 6.31에서 6.60으로, HumanEval을 61.0에서 62.2로 향상시켰습니다. Auto Evol-Instruct 프레임워크는 이런 초기 진화 방법을 기반으로 추가적인 향상의 가능성을 보여줍니다. GSM8K에서 Auto Evol-Instruct는 성능을 62.7에서 64.4로 향상시킬 수 있었습니다. 이런 결과는 제안된 방법이 초기 진화 방법을 효과적으로 최적화하여 다양한 벤치마크에서 개선을 이끌어낼 수 있음을 강조합니다.
5.2 다중 최적화의 효과
Auto Evol-Instruct에서 다중 최적화의 영향을 탐구하고, GSM8K에서 ablations을 수행합니다. Auto Evol-Instruct의 기본 하이퍼파라미터를 유지하면서 최적화 횟수의 영향을 탐구합니다. Figure 5(a)는 최적화 횟수를 증가시키면 데이터 효율성이 눈에 띄게 향상되는 패턴을 보여줍니다. 예를 들어, 최적화 횟수를 1로 설정하면 GSM8K에서 62.7을 달성하고, 최적화 횟수를 9로 증가시키면 정확도가 65.0으로 향상됩니다. 그러나 최적화 횟수가 증가하면 리소스 소비도 증가할 수 있습니다. 적은 최적화는 현재 진화 방법의 집중적인 개선을 초래할 수 있지만, 이는 진화 방법의 잠재력을 완전히 활용하지 못할 수 있습니다.
5.3 다양한 진화 LLM
Auto Evol-Instruct를 다양한 진화 LLM과 통합했을 때의 성능을 평가합니다. Table 3은 GPT-3.5와 GPT-4를 사용하여 GSM8K를 진화시켰을 때의 영향을 보여줍니다. 특히, GPT-4를 진화 LLM으로 사용할 때, 방법은 GPT-3.5에서 64.4에서 70.7로 성능이 향상됩니다. 이런 결과는 다양한 진화 LLM에서 프레임워크가 널리 적용 가능하고 효과적임을 명확하게 보여줍니다.
| Method | Evol LLM | GSM8K |
|---|---|---|
| Seed Data | - | 56.9 |
| Evol Instruct | GPT-3.5 | 61.4 |
| Evol Instruct | GPT-4 | 63.2 |
| Auto Evol-Instruct | GPT-3.5 | 64.4 |
| Auto Evol-Instruct | GPT-4 | 70.7 |
5.4 혼합 라운드 스케일링
GSM8K에서 다양한 라운드의 진화 데이터를 혼합하여 데이터 스케일링 효과를 평가합니다. Figure 6은 방법이 Evol Instruct에 비해 우수한 확장성을 갖는 것을 강조합니다. 방법의 1라운드 데이터는 Evol Instruct의 1라운드와 2라운드의 혼합 데이터보다 뛰어납니다.
5.5 복잡성과 다양성의 논의
Liu et al. (2023b)는 데이터셋의 복잡성과 다양성이 모델 정렬에 중요한 영향을 미친다고 강조합니다. Instag의 자동 태그 방법을 사용하여 다양한 기술을 사용하여 100개의 지시를 진화시켰습니다. Table 4는 데이터가 더 다양하고 복잡해질수록 모델 성능이 크게 향상된다는 명확한 상관관계를 확인합니다. Evol Instruct는 원래의 코드 alpaca를 개선하여 다양성을 1.95에서 2.37로, 복잡성을 4.06에서 4.55로 증가시켰습니다. 이런 개선은 HumanEval의 눈에 띄는 향상으로 이어졌으며, 57.9에서 64.0으로 상승했습니다.
| Math | Diversity | Complexity | GSM8K |
|---|---|---|---|
| GSM8K Training | 1.39 | 4.82 | 56.9 |
| Evol Instruct | 1.69 | 4.90 | 61.4 |
| Auto Evol-Instruct | 2.2 | 5.54 | 64.4 |
| Chat | Diversity | Complexity | MT-Bench |
| Alpaca | 2.16 | 2.70 | 5.95 |
| Evol Instruct | 3.15 | 3.63 | 6.31 |
| Auto Evol-Instruct | 3.19 | 3.89 | 6.71 |
| Code | Diversity | Complexity | HumanEval |
| Code Alpaca | 1.95 | 4.06 | 57.9 |
| Evol Instruct | 2.37 | 4.55 | 61.0 |
| Auto Evol-Instruct | 3.05 | 5.18 | 64.0 |
6. 결론
Auto Evol-Instruct는 다양한 작업에서 우수한 성능을 발휘하는 자동화된 지시 데이터 개선 프레임워크입니다. 실험 결과, 자동화된 방법이 수동 방법을 능가하며, 지시 따라하기, 수학적 인퍼런스, 코드 생성 등 여러 작업에서 향상된 성능을 보였습니다.