Character.AI - Optimizing AI Inference
- Related Project: Private
- Category: Paper Review
- Date: 2024-06-20
Optimizing AI Inference at Character.AI
- url: https://research.character.ai/optimizing-inference/
- abstract: At Character.AI, we aim to integrate AGI into daily life, enhancing areas such as business, education, and entertainment through efficient “inference” processes in LLMs. We design our models to optimize inference, making it cost-effective and scalable for a global audience. Currently, we handle over 20,000 inference queries per second, about 20% of Google Search’s volume. Our innovations include a memory-efficient architecture that significantly reduces the size of the cache needed for attention mechanisms, allowing us to handle larger batch sizes without increasing GPU memory requirements. Techniques like Multi-Query Attention and Hybrid Attention Horizons, along with Cross Layer KV-sharing, reduce the cache size by more than 20X. Additionally, our stateful caching system conserves resources by maintaining attention KV on host memory between chat turns, achieving a 95% cache rate and minimizing the cost of inference. Moreover, we use int8 quantization for model weights and activations to improve training efficiency and reduce the risk of mismatches between training and serving configurations. These advancements have led to a reduction in serving costs by a factor of 33 since late 2022, making our systems significantly more economical compared to leading commercial APIs. At Character.AI, we continue to advance the capabilities of LLMs, aiming to make efficient and scalable AI systems central to everyday interactions.
TL;DR
- 현재 인퍼런스 상황: 포스팅 시점에서 Character.AI는 초당 20,000개 이상의 인퍼런스 쿼리를 처리하는데, 이는 Google 검색 요청량의 약 20%에 해당합니다.
- 아키텍처: 메모리 효율적인 아키텍처 설계를 통해 GPU 메모리가 더 이상 대규모 배치 크기를 서비스하는데 있어 병목 현상이 되지 않도록 Multi-Query Attention, Hybrid Attention Horizons, Cross Layer KV-sharing 적용을 통해 KV 캐시 크기를 20배 이상 줄였다고 합니다.
- 상태 유지 캐싱: 대화가 길어짐에 따라 계속해서 KV 캐시를 채우는 것은 비용이 많이 듭니다. 이를 해결하기 위해, 대화 간 KV를 호스트 메모리에 캐싱하는 효율적인 시스템을 개발하였는데, 캐시 재사용을 가능하게 하여 인퍼런스 비용을 추가로 절감했다고 합니다.
- 훈련 및 서빙을 위한 양자화: 모델의 가중치, 활성화, 어텐션 KV 캐시에 int8 양자화를 사용하며, 이는 훈련과 서빙 간의 불일치 위험을 제거하고 훈련 효율을 크게 향상시켰다고 언급합니다.
주요 기법으로는 다중 쿼리 어텐션 메커니즘, 지역-전역 어텐션 계층의 혼용, 그리고 계층 간 KV 캐시 공유로 이를 통해 KV 캐시 크기를 20배 이상 축소하여 GPU 메모리 병목 현상을 해소하였다고 합니다. 이는 \(O(n^2)\) 복잡도를 가진 어텐션 연산의 효율을 개선하고, 롤링 해시를 통해 부분 일치 메시지에 대해서도 캐시를 활용할 수 있게 했다고 합니다.
또한, 대화형 시스템에서의 장기 문맥 처리를 위해 호스트 메모리 기반의 상태 유지 캐싱 시스템을 개발하였는데, 이 시스템은 롤링 해시 기반의 LRU 캐시 구조를 채택하여 부분 일치 메시지에 대해서도 효율적인 캐시 재사용이 가능해 결과적으로 95%의 캐시 적중률을 달성하여 인퍼런스 비용을 절감하였다고 합니다.
Memory-efficient Architecture Design
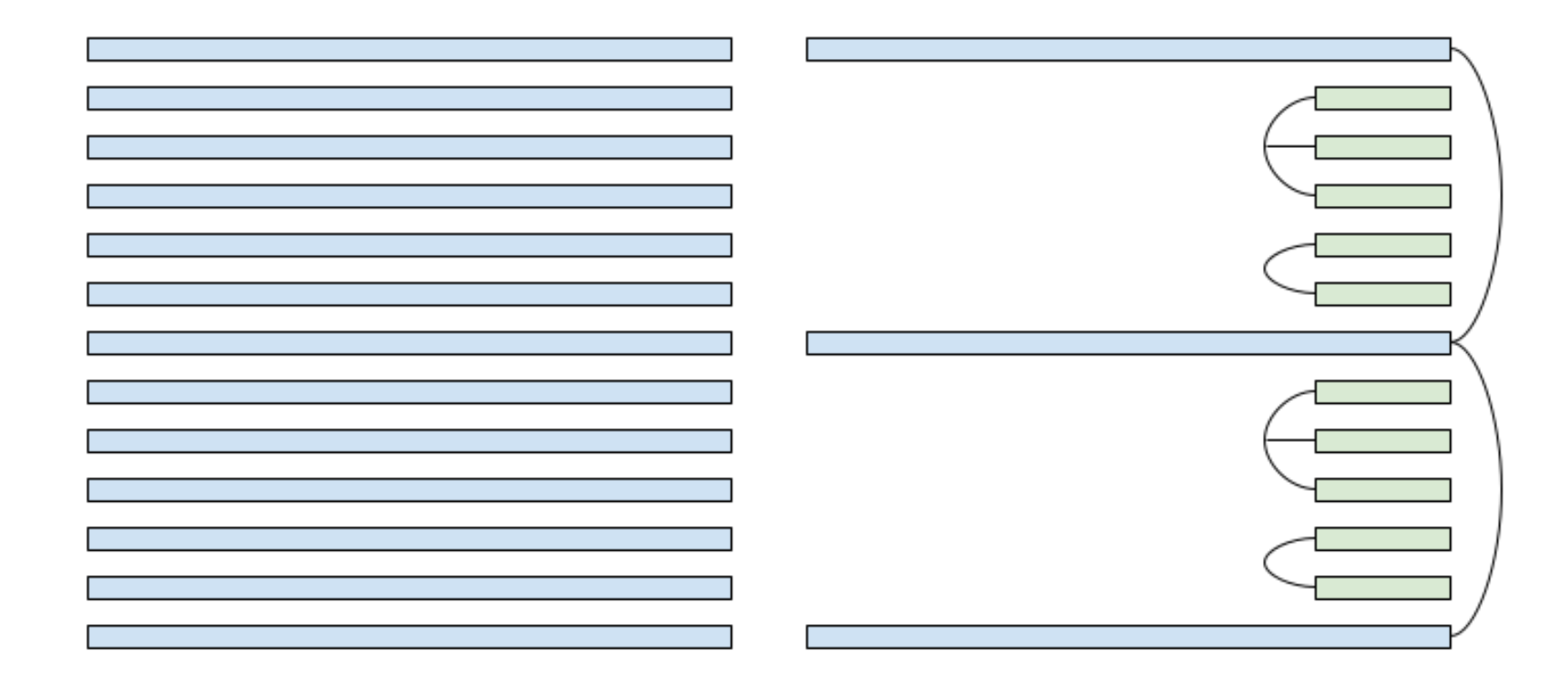
Figure 1. Left: Standard transformer design where every attention is global attention. Right: The attention design in our production model. Blue boxes indicate global attention, green boxes indicate local attention, and curves indicate KV-sharing. For global attention layers, we share KV across multiple non-adjacent layers. This illustration depicts only a subset of the layers in the full model.
The key bottleneck of LLM inference throughput is the size of the cache of attention keys and values (KV). It not only determines the maximum batch size that can fit on a GPU, but also dominates the I/O cost on attention layers. We use the following techniques to reduce KV cache size by more than 20X without regressing quality. With these techniques, GPU memory is no longer a bottleneck for serving large batch sizes.
- Multi-Query Attention. We adopt Multi-Query Attention (Shazeer, 2019) in all attention layers. This reduces KV cache size by 8X compared to the Grouped-Query Attention adopted in most open source models.
- Hybrid Attention Horizons. We interleave local attention (Beltagy et al., 2020) with global attention layers. Local attention is trained with sliding windows, and reduces the complexity from O(length2) to O(length). We found that reducing attention horizon to 1024 on most attention layers does not have a significant impact on evaluation metrics, including the long context needle-in-haystack benchmark. In our production model, only 1 out of every 6 layers uses global attention.
- Cross Layer KV-sharing. We tie the KV cache across neighboring attention layers, which further reduces KV cache size by a factor of 2-3x. For global attention layers, we tie the KV cache of multiple global layers across blocks, since the global attention layers dominate the KV cache size under long context use cases. Similar to a recent publication (Brandon et al., 2024), we find that sharing KV across layers does not regress quality.
Stateful Caching
One of our key innovations is an efficient system for caching attention KV on host memory between chat turns. On Character.AI, the majority of chats are long dialogues; the average message has a dialogue history of 180 messages. As dialogues grow longer, continuously refilling KV caches on each turn would be prohibitively expensive.
To solve this problem, we developed an inter-turn caching system. For every prefilled prefix and generated message, we cache the KV values on host memory and retrieve them for future queries. Similar to RadixAttention (Zheng et al., 2023), we organize cached KV tensors in a LRU cache with a tree structure. The cached KV values are indexed by a rolling hash of prefix tokens. For each new query, a rolling hash is calculated for each prefix of the context, and the cache is retrieved for the longest match. This allows reusing the cache even for partially matched messages.
At a fleet level, we use sticky sessions to route the queries from the same dialogue to the same server. Since our KV cache size is small, each server can cache thousands of dialogues concurrently. Our system achieves a 95% cache rate, further reducing inference cost.
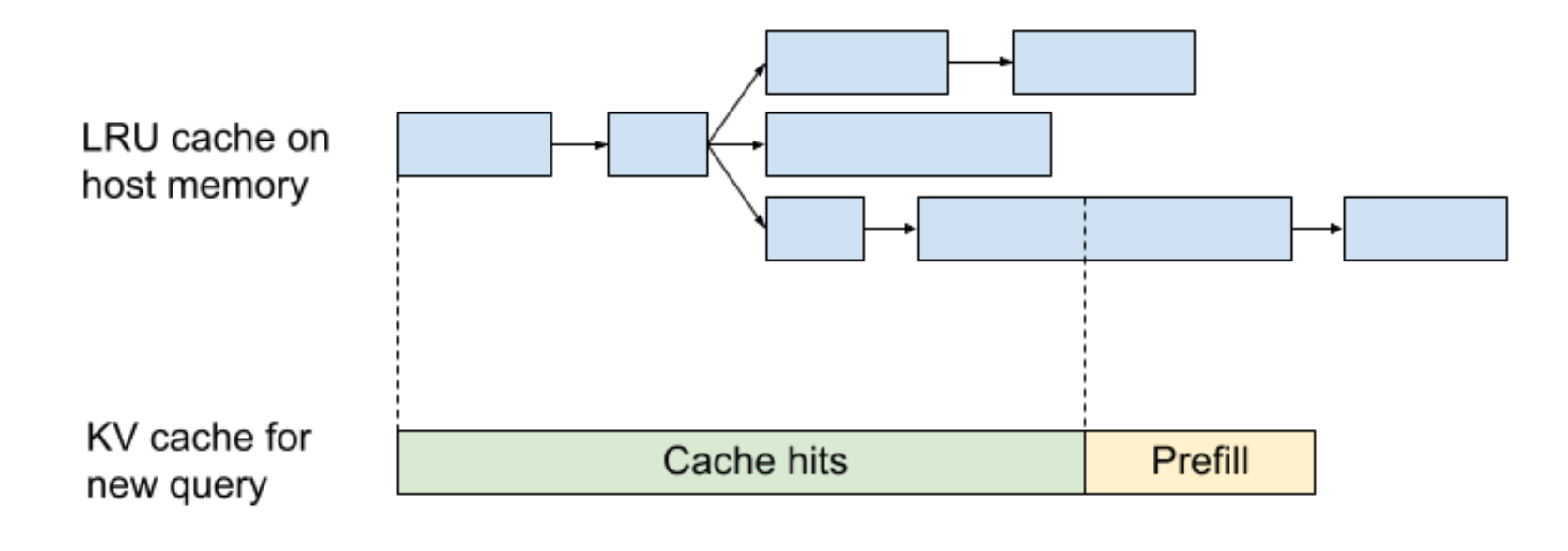
Figure 2. Blue boxes indicate cached tensors on host memory. Green and yellow boxes indicate KV cache on CUDA memory. When a new query arrives, it retrieves the KV cache for the longest matched prefix. Our rolling hash system allows retrieving cache for partially matched messages.