Evaluation | Human vs. LLM judges
- Related Project: Private
- Category: Paper Review
- Date: 2024-06-26
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
- url: https://arxiv.org/abs/2406.18403
- pdf: https://arxiv.org/pdf/2406.18403
- html: https://arxiv.org/html/2406.18403v1
- abstract: There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
TL;DR
- 자연어 처리(NLP) 과제 평가에는 휴먼 판단이 필수적입니다.
- 최신 LLM은 휴먼의 판단을 대체하려 하나, 오차 및 편향이 존재합니다.
- 본 연구에서는 다양한 데이터셋을 이용하여 LLM의 판단력을 분석하였습니다.
1. 서론
최근 자연어 처리(NLP) 과제에서는 모델 출력에 대한 평가를 자동화하려는 경향이 있습니다. 이런 평가는 전통적으로 휴먼이 수행하였으나, 대규모 언어모델(LLM)을 이용한 자동 평가로 전환되고 있습니다. 예를 들어, LLM은 대화 시스템 응답의 가능성을 1에서 5까지 평가하도록 지시받을 수 있습니다. 이는 평가 작업을 간소화하고 여러 평가 라운드에 걸쳐 더 신뢰할 수 있는 결과를 얻을 수 있다고 주장됩니다. 그러나 LLM이 휴먼과는 다른 오류나 체계적 편향을 가질 수 있으므로, 이는 평가 결과를 왜곡시키고 잘못된 결론을 낳을 수 있습니다. 특히 폐쇄 모델의 경우 재교육이나 모델 변경이 언제든지 일어날 수 있으므로, 비교 가능성이 떨어질 수 있습니다.
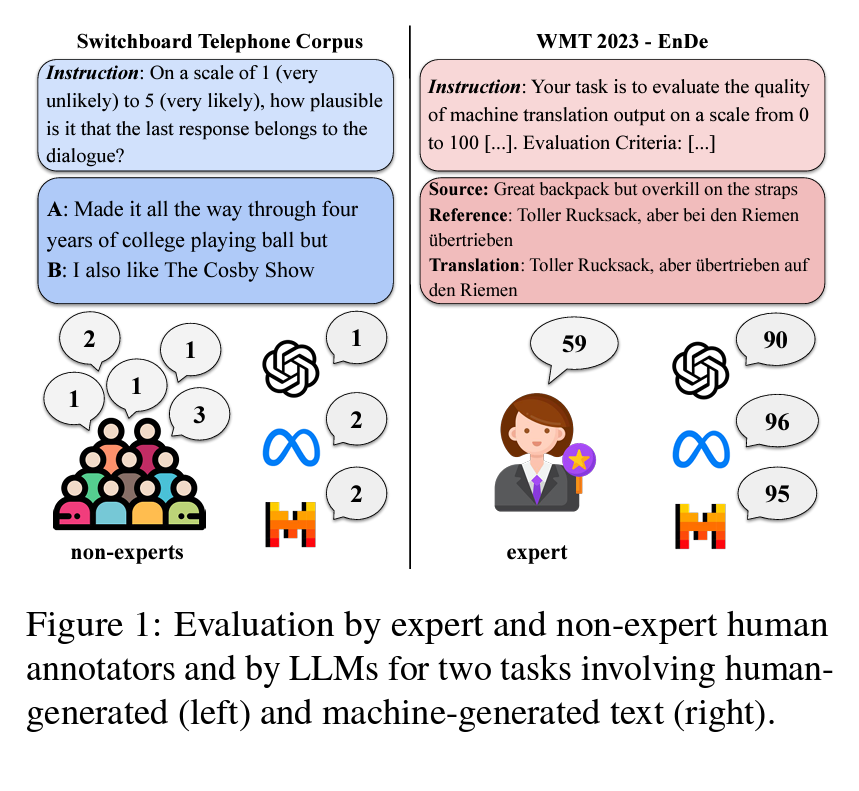
2. Judge-Bench 구성
Judge-Bench는 휴먼이 주석을 단 20개의 데이터셋을 포함하는 평가 체계입니다. 이 데이터셋들은 품질 차원이 다양하며, 텍스트의 문법성, 독성, 일관성 등 여러 속성을 평가합니다. 데이터셋은 모델 생성 텍스트와 휴먼 생성 텍스트 두 가지 유형으로 나뉩니다. 각 데이터셋은 그에 맞는 속성에 대해 평가를 실시합니다. 이런 구조는 연구자들이 새로운 데이터셋을 쉽게 통합할 수 있는 유연한 벤치마크를 제공합니다.
3. 모델 선택 및 실험 설계
다양한 크기와 성능의 대표적인 LLM을 선택하였고, 이들 모델은 열린 가중치 모델과 소유권이 있는 모델로 구분됩니다. 평가는 주어진 데이터셋의 휴먼 판단 지침을 바탕으로 모델을 프롬프트하여 실행됩니다. 실험 결과는 모델이 요청한 대로 응답하지 않을 때 무효 응답을 무작위 값으로 대체하여 일관된 판단 수를 유지하는 방식으로 처리합니다. 평가는 스피어만의 상관 관계와 코헨의 카파를 사용하여 계산됩니다.
4. 결과
LLM의 성능은 데이터셋과 평가하는 속성에 따라 크게 다양했습니다. 일부 LLM은 휴먼 판단과 잘 일치하는 반면, 다른 LLM은 상당한 차이를 보였습니다. 특히 독성과 안전성 평가에서는 낮은 점수와 응답률을 보이는 경우가 많았습니다. 다양한 모델의 평가 결과를 종합해보면, 특정 모델이 모든 평가에서 우수하다고는 할 수 없으며, 다양한 품질 차원이 서로 다른 모델에 의해 더 잘 평가됩니다. 모든 모델은 휴먼 언어 평가에서 더 높은 일치도를 보였습니다.