LLM Abliteration**
- Related Project: Private
- Project Status: 1 Alpha
- Date: 2024-06-13
Uncensor any LLM with abliteration
- url: https://huggingface.co/blog/mlabonne/abliteration
- abstract: The third generation of Llama models includes fine-tuned (Instruct) versions that are adept at understanding and following instructions but are heavily censored to avoid harmful outputs. This article introduces a technique called “abliteration” to uncensor any language model without retraining, effectively removing the model’s built-in refusal mechanism. We explore the technical steps involved in this process and provide code implementations. The article also discusses the performance implications and how further training can restore the model’s quality after uncensoring.
[Llama의 safety 제거 예시, 절제 및 웨이트 제거 색인마킹]
Contents
- Uncensor any LLM with abliteration
TL;DR
언어 모델의 검열 해제: Abliteration 기법 탐구
- 재훈련 없이 언어 모델의 검열을 해제하는 abliteration 기법 소개
- 수학적 공식 포함한 단계별 방법 상세 설명
- 모델 품질을 회복하기 위한 DPO로 성능 평가 및 파인튜닝
개요
Llama-3는 instruction를 이해하고 따르는 데 향상된 파인튜닝(Instruct) 버전을 제공했지만, 메타의 개발 기조 상 안전성을 위해 강하게 유해 콘텐츠 검열이 동시에 학습되어 있습니다. (Meta는 safety와 helpfulness의 균형, 특히 safety에 대한 심도깊은 연구를 진행하였음. LLaMA-2, 3 논문/페이지 등 참조) 이런 안전 기능은 남용을 방지하는 데 중요하지만 모델의 유연성과 반응을 제한할 수 있습니다. (safety로 인해 답변을 거부하는 등의 직/간접적인 가드레일이 적용되어 있으며, 모델 웨이트에 적용되어있으므로)
허깅 페이스의 Maxime Labonne 포스트에서는 6XA6000로 약 7시간을 학습하여 Abliteration이라는 기법으로 재훈련 없이(회복을 위한 일부 조정은 포함) LLM의 검열을 해제하는 방법을 설명합니다. 이 기법은 모델의 내장된 거부 메커니즘을 효과적으로 제거하여 모든 종류의 프롬프트에 응답할 수 있게 하지만, 포스트의 결과를 보면, 성능 저하도 같이 수반하게 되는 것을 확인할 수 있습니다. Anthropic의 연구 기조(Toy Model 및 후속 논문)와 다른 연구팀에서의 탐구 방식과 동일하지만, 간단하게 가능성을 탐구합니다.
그러나 회복을 위한 데이터셋이나 safety에 대한 검열만 제거되고, 다른 LLM의 성능에 영향을 미치는지는 광범위한 리소스가 필요하기 때문에 포스트 형식으로 발표합니다.
Abliteration이란?
현대의 LLM은 안전 및 instruction 준수를 위해 파인튜닝됩니다. 이는 유해한 요청을 거부하도록 훈련된 것을 의미합니다. Arditi 등은 블로그 게시물에서 이런 거부 행동이 모델의 잔류 스트림에 특정 방향으로 매개된다고 보여주었습니다. 이 방향을 모델이 표현하지 못하도록 하면 요청을 거부할 수 없게 됩니다. 반대로 이 방향을 인위적으로 추가하면 모델이 무해한 요청조차 거부할 수 있습니다.
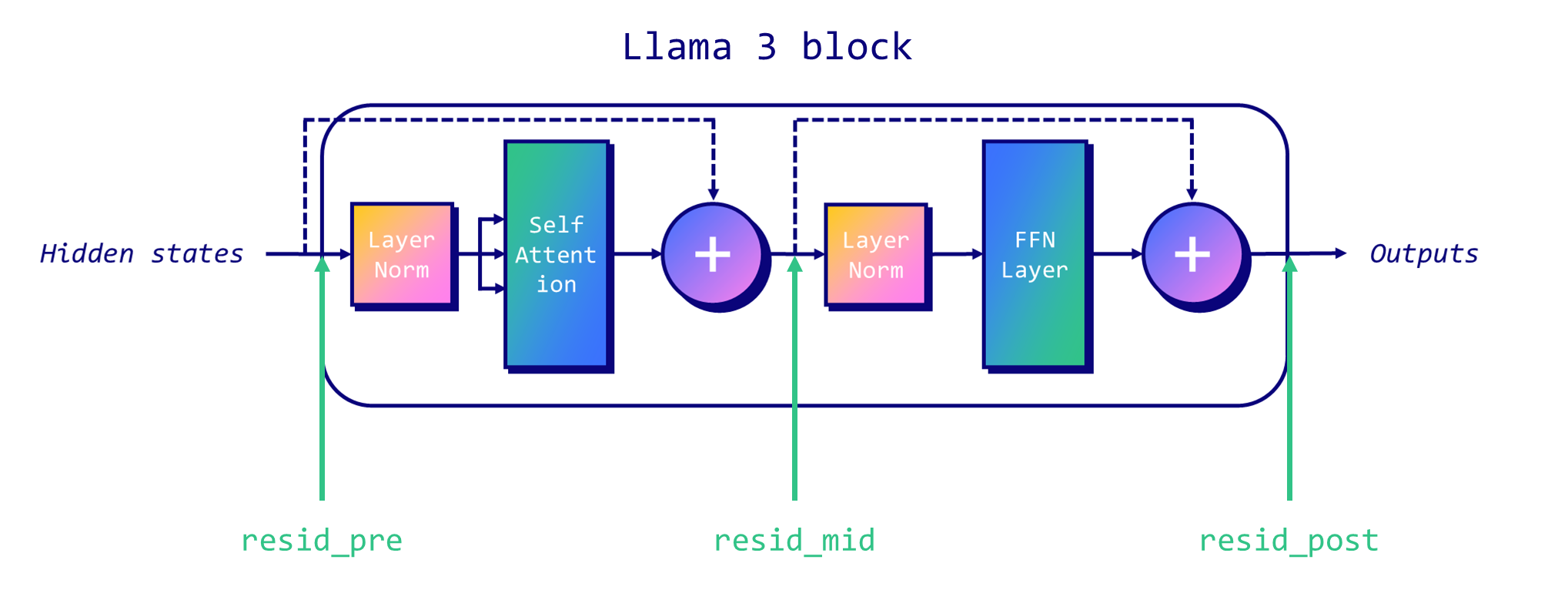
전통적인 디코더 전용 Llama-like 아키텍처에서는 각 블록의 시작(pre), 어텐션과 MLP 레이어 사이(mid), MLP 이후(post)에 세 가지 잔류 스트림이 있습니다.
다음 Figure은 각 잔류 스트림의 위치를 보여줍니다.
방법
- 인퍼런스 시 개입: 잔류 스트림에 쓰는 모든 구성 요소(e.g., 어텐션 헤드)에 대해 출력의 거부 방향으로의 투영을 계산하고 이 투영을 뺍니다. 이 차감은 모든 토큰과 모든 레이어에서 적용되어 모델이 거부 방향을 결코 나타내지 않도록 합니다.
- 가중치 직교화: 모델 가중치를 직접 수정합니다. 구성 요소 가중치를 거부 방향에 대해 직교화함으로써 이 방향으로 쓰지 않도록 합니다.
위 과정을 FailSpy 노트북을 기반으로 구현하고, TransformerLens 라이브러리를 사용해 기계적 해석을 수행합니다.
- 데이터 로딩: 유해한 instruction와 무해한 instruction 데이터셋을 로드합니다.
- 모델 로딩 및 토큰화: abliteration할 모델을 로드합니다.
- 데이터 토큰화 및 수집: 데이터셋을 토큰화하고, 잔류 스트림 활성화를 저장합니다.
- 거부 방향 계산: 각 레이어에 대한 거부 방향을 계산합니다.
- 평가: 인퍼런스 중에 거부 방향을 적용하여 평가합니다.
- 가중치 직교화: 가장 좋은 거부 방향을 선택하고 모델의 가중치를 직교화합니다.
1. 벡터 수집
1.1. 데이터 수집
데이터 수집 및 잔류 스트림 활성화 기록
모델을 유해한 instruction 데이터셋과 무해한 instruction 데이터셋에서 실행하여 마지막 토큰 위치의 잔류 스트림 활성화를 각각 기록합니다.
잔류 스트림은 다음과 같은 식으로 나타낼 수 있습니다.
\[R^{(l)} = H^{(l-1)} + A^{(l)}(H^{(l-1)}) + M^{(l)}(A^{(l)}(H^{(l-1)}))\]\(R^{(l)}\)는 \(l\) 번째 레이어의 잔류 스트림, \(H^{(l-1)}\)는 이전 레이어의 출력, \(A^{(l)}\)는 주의(attention) 기법, \(M^{(l)}\)는 MLP 계층을 의미합니다.
# Define batch size based on available VRAM
batch_size = 32
# Initialize defaultdicts to store activations
harmful = defaultdict(list)
harmless = defaultdict(list)
# Process the training data in batches
num_batches = (n_inst_train + batch_size - 1) // batch_size
for i in tqdm(range(num_batches)):
print(i)
start_idx = i * batch_size
end_idx = min(n_inst_train, start_idx + batch_size)
# Run models on harmful and harmless prompts, cache activations
harmful_logits, harmful_cache = model.run_with_cache(
harmful_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
)
harmless_logits, harmless_cache = model.run_with_cache(
harmless_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
)
# Collect and store the activations
for key in harmful_cache:
harmful[key].append(harmful_cache[key])
harmless[key].append(harmless_cache[key])
# Flush RAM and VRAM
del harmful_logits, harmless_logits, harmful_cache, harmless_cache
gc.collect()
torch.cuda.empty_cache()
# Concatenate the cached activations
harmful = {k: torch.cat(v) for k, v in harmful.items()}
harmless = {k: torch.cat(v) for k, v in harmless.items()}
1.2. 평균 차이 계산
유해한 instruction와 무해한 instruction의 활성화 평균 차이 계산
각 레이어에서 유해한 instruction와 무해한 instruction의 활성화 평균 차이를 계산하고, 모델의 각 레이어에 대한 거부 방향을 나타내는 벡터를 얻습니다.
평균 차이는 다음과 같이 계산합니다.
\[D^{(l)} = \frac{1}{n} \sum_{i=1}^{n} R_h^{(l,i)} - \frac{1}{m} \sum_{j=1}^{m} R_{nh}^{(l,j)}\]\(D^{(l)}\)는 \(l\) 번째 레이어의 평균 차이, \(R_h^{(l,i)}\)는 유해한 instruction에 대한 \(l\) 번째 레이어의 \(i\) 번째 잔류 스트림, \(R_{nh}^{(l,j)}\)는 무해한 instruction에 대한 \(l\) 번째 레이어의 \(j\) 번째 잔류 스트림입니다.
# Helper function to get activation index
def get_act_idx(cache_dict, act_name, layer):
key = (act_name, layer)
return cache_dict[utils.get_act_name(*key)]
# Compute difference of means between harmful and harmless activations at intermediate layers
activation_layers = ["resid_pre", "resid_mid", "resid_post"]
activation_refusals = defaultdict(list)
for layer_num in range(1, model.cfg.n_layers):
pos = -1 # Position index
for layer in activation_layers:
harmful_mean_act = get_act_idx(harmful, layer, layer_num)[:, pos, :].mean(dim=0)
harmless_mean_act = get_act_idx(harmless, layer, layer_num)[:, pos, :].mean(
dim=0
)
refusal_dir = harmful_mean_act - harmless_mean_act
refusal_dir = refusal_dir / refusal_dir.norm()
activation_refusals[layer].append(refusal_dir)
1.3. 선택 및 정규화
벡터 정규화 및 가장 높은 거부 방향 선택
위에서 수집한 벡터들을 정규화하고 평가하여 단일 가장 높은 거부 방향을 선택합니다. 정규화는 벡터를 단위 벡터로 변환하며, 정규화된 벡터는 다음과 같이 계산됩니다.
\[\hat{D}^{(l)} = \frac{D^{(l)}}{\|D^{(l)}\|}\]정규화된 벡터를 사용하여 단일 가장 높은 거부 방향을 선택합니다.
selected_layers = ["resid_pre"]
activation_scored = sorted(
[
activation_refusals[layer][l - 1]
for l in range(1, model.cfg.n_layers)
for layer in selected_layers
],
key=lambda x: abs(x.mean()),
reverse=True,
)
2. 인퍼런스 시 개입 단계
2.1. 인퍼런스 시 개입 및 잔류 스트림 수정
각 구성 요소가 잔류 스트림에 쓰는 출력을 거부 방향으로의 투영을 계산하고 이를 뺍니다. 이 과정은 다음과 같은 수식으로 표현됩니다.
\[R'^{(l)} = R^{(l)} - (R^{(l)} \cdot \hat{D}^{(l)}) \hat{D}^{(l)}\]\(R'^{(l)}\)는 수정된 잔류 스트림, \(R^{(l)}\)는 원래 잔류 스트림, \(\hat{D}^{(l)}\)는 정규화된 거부 방향입니다.
# Inference-time intervention hook
def direction_ablation_hook(
activation: Float[Tensor, "... d_act"],
hook: HookPoint,
direction: Float[Tensor, "d_act"],
):
if activation.device != direction.device:
direction = direction.to(activation.device)
proj = (
einops.einsum(
activation, direction.view(-1, 1), "... d_act, d_act single -> ... single"
)
* direction
)
return activation - proj
3. 가중치 직교화
3.1. 가중치 직교화 및 거부 방향 제거
모델 가중치를 거부 방향에 대해 직교화하여 이 방향으로 쓰지 않도록 해서 유해한 컨텐츠를 검열하는 레이어를 제거합니다. 가중치 직교화는 다음과 같이 계산됩니다.
\[W' = W - (W \cdot \hat{D}) \hat{D}\]\(W\)는 원래 가중치 행렬, \(\hat{D}\)는 정규화된 거부 방향, \(W'\)는 직교화된 가중치 행렬입니다.
def get_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"], vec: Float[Tensor, "d_model"]
) -> Float[Tensor, "... d_model"]:
proj = (
einops.einsum(
matrix, vec.view(-1, 1), "... d_model, d_model single -> ... single"
)
* vec
)
return matrix - proj
# Select the layer with the highest potential refusal direction
LAYER_CANDIDATE = 9
refusal_dir = activation_scored[LAYER_CANDIDATE]
# Orthogonalize the model's weights
if refusal_dir.device != model.W_E.device:
refusal_dir = refusal_dir.to(model.W_E.device)
model.W_E.data = get_orthogonalized_matrix(model.W_E, refusal_dir)
for block in tqdm(model.blocks):
if refusal_dir.device != block.attn.W_O.device:
refusal_dir = refusal_dir.to(block.attn.W_O.device)
block.attn.W_O.data = get_orthogonalized_matrix(block.attn.W_O, refusal_dir)
block.mlp.W_out.data = get_orthogonalized_matrix(block.mlp.W_out, refusal_dir)
# Generate text with abliterated model
orthogonalized_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
)
# Print generations
for i in range(N_INST_TEST):
if len(baseline_generations) > i:
print(f"INSTRUCTION {i}: {harmful_inst_test[i]}")
print(f"\033[92mBASELINE COMPLETION:\n{baseline_generations[i]}")
print(f"\033[91mINTERVENTION COMPLETION:\n{evals[LAYER_CANDIDATE][i]}")
print(f"\033[95mORTHOGONALIZED COMPLETION:\n{orthogonalized_generations[i]}\n")
DPO
Abliteration 후 모델의 성능을 회복하기 위해 가장 간단한 Alignment tuning 방법인 DPO(Direct Preference Optimization)를 사용합니다. 모델은 DeepSpeed ZeRO-2를 사용하여 6xA6000 GPU에서 약 6시간 45분 동안 훈련되었으며, 훈련 곡선은 추가 훈련을 통해 abliteration으로 인한 성능 저하를 대부분 회복할 수 있음을 보여줍니다.
최종 모델, NeuralDaredevil-8B는 완전히 검열을 제거한 8B LLM입니다.
결론
이 글에서는 abliteration 개념을 소개합니다. 이 기법으로 무해한 프롬프트와 유해한 프롬프트에 대한 모델의 활성화를 사용하여 거부 방향을 계산합니다. 그런 다음 이 방향을 사용하여 모델의 가중치를 수정하여 검열 레이어를 제거합니다. Abliteration 후, DPO 파인튜닝을 통해 모델의 성능을 회복하여 완전히 검열이 해제된 8B 카테고리 LLM을 생성합니다.
1 Abstract
The third generation of Llama models includes fine-tuned (Instruct) versions that are adept at understanding and following instructions but are heavily censored to avoid harmful outputs. This article introduces a technique called “abliteration” to uncensor any language model without retraining, effectively removing the model’s built-in refusal mechanism. We explore the technical steps involved in this process and provide code implementations. The article also discusses the performance implications and how further training can restore the model’s quality after uncensoring.
2 Introduction
The third generation of Llama models provided fine-tunes (Instruct) versions that excel in understanding and following instructions. However, these models are heavily censored, designed to refuse requests seen as harmful with responses such as “As an AI assistant, I cannot help you.” While this safety feature is crucial for preventing misuse, it limits the model’s flexibility and responsiveness.
In this article, we will explore a technique called “abliteration” that can uncensor any LLM without retraining. This technique effectively removes the model’s built-in refusal mechanism, allowing it to respond to all types of prompts.
The code is available on Google Colab and in the LLM Course on GitHub.
3 What is Abliteration?
Modern LLMs are fine-tuned for safety and instruction-following, meaning they are trained to refuse harmful requests. In their blog post, Arditi et al. have shown that this refusal behavior is mediated by a specific direction in the model’s residual stream. If we prevent the model from representing this direction, it loses its ability to refuse requests. Conversely, adding this direction artificially can cause the model to refuse even harmless requests.
In the traditional decoder-only Llama-like architecture, there are three residual streams we can target: at the start of each block (“pre”), between the attention and MLP layers (“mid”), and after the MLP (“post”). The following figure illustrates the location of each residual stream.
4 Implementation Steps
Data Collection
- Run the model on a set of harmful instructions and a set of harmless instructions, recording the residual stream activations at the last token position for each.
- Mean Difference Calculation: Calculate the mean difference between the activations of harmful and harmless instructions. This gives us a vector representing the “refusal direction” for each layer of the model.
- Selection: Normalize these vectors and evaluate them to select the single best “refusal direction.”
Abliteration
- Inference-Time Intervention: For every component that writes to the residual stream (such as an attention head), calculate the projection of its output onto the refusal direction and subtract this projection. This subtraction is applied at every token and every layer, ensuring that the model never represents the refusal direction.
- Weight Orthogonalization: Modify the model weights directly. By orthogonalizing the component weights with respect to the refusal direction, it prevents the model from writing to this direction altogether.
5 Code Implementation
5.1 Setup
The following implementation of abliteration is based on FailSpy’s notebook. It uses the TransformerLens library for mechanistic interpretability.
!pip install transformers transformers_stream_generator tiktoken transformer_lens einops jaxtyping
import torch
import functools
import einops
import gc
from datasets import load_dataset
from tqdm import tqdm
from torch import Tensor
from typing import List
from transformer_lens import HookedTransformer, utils
from transformer_lens.hook_points import HookPoint
from transformers import AutoModelForCausalLM, AutoTokenizer
from jaxtyping import Float, Int
from collections import defaultdict
# Turn automatic differentiation off to save GPU memory (credit: Undi95)
torch.set_grad_enabled(False)
5.2 Data Loading
Load the harmful and harmless instruction datasets.
def reformat_texts(texts):
return [[{"role": "user", "content": text}] for text in texts]
def get_harmful_instructions():
dataset = load_dataset('mlabonne/harmful_behaviors')
return reformat_texts(dataset['train']['text']), reformat_texts(dataset['test']['text'])
def get_harmless_instructions():
dataset = load_dataset('mlabonne/harmless_alpaca')
return reformat_texts(dataset['train']['text']), reformat_texts(dataset['test']['text'])
harmful_inst_train, harmful_inst_test = get_harmful_instructions()
harmless_inst_train, harmless_inst_test = get_harmless_instructions()
5.3 Model Loading
Load the model to be abliterated.
MODEL_ID = "mlabonne/Daredevil-8B"
MODEL_TYPE = "meta-llama/Meta-Llama-3-8B-Instruct"
!git clone https://huggingface.co/{MODEL_ID} {MODEL_TYPE}
model = HookedTransformer.from_pretrained_no_processing(
MODEL_TYPE,
local_files_only=True,
dtype=torch.bfloat16,
default_padding_side='left'
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_TYPE)
tokenizer.padding_side = 'left'
tokenizer.pad_token = tokenizer.eos_token
5.4 Tokenization
Tokenize the datasets.
def tokenize_instructions(tokenizer, instructions):
return tokenizer.apply_chat_template(
instructions,
padding=True,
truncation=False,
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
).input_ids
n_inst_train = min(256, len(harmful_inst_train), len(harmless_inst_train))
harmful_tokens = tokenize_instructions(
tokenizer,
instructions=harmful_inst_train[:n_inst_train],
)
harmless_tokens = tokenize_instructions(
tokenizer,
instructions=harmless_inst_train[:n_inst_train],
)
5.5 Data Collection
Process tokenized datasets and store residual stream activations.
batch_size = 32
harmful = defaultdict(list)
harmless = defaultdict(list)
num_batches = (n_inst_train + batch_size - 1) // batch_size
for i in tqdm(range(num_batches)):
start_idx = i * batch_size
end_idx = min(n_inst_train, start_idx + batch_size)
harmful_logits, harmful_cache = model.run_with_cache(
harmful_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
)
harmless_logits, harmless_cache = model.run_with_cache(
harmless_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
)
for key in harmful_cache:
harmful[key].append(harmful_cache[key])
harmless[key].append(harmless_cache[key])
del harmful_logits, harmless_logits, harmful_cache, harmless_cache
gc.collect()
torch.cuda.empty_cache()
harmful = {k: torch.cat(v) for k, v in harmful.items()}
harmless = {k: torch.cat(v) for k, v in harmless.items()}
5.6 Refusal Direction Calculation
Compute the refusal direction for each layer.
def get_act_idx(cache_dict, act_name, layer):
key = (act_name, layer)
return cache_dict[utils.get_act_name(*key)]
activation_layers = ["resid_pre", "resid_mid", "resid_post"]
activation_refusals = defaultdict(list)
for layer_num in range(1, model.cfg.n_layers):
pos = -1
for layer in activation_layers:
harmful_mean_act = get_act_idx(harmful, layer, layer_num)[:, pos, :].mean(dim=0)
harmless_mean_act = get_act_idx(harmless, layer, layer_num)[:, pos, :].mean(dim=0)
refusal_dir = harmful_mean_act - harmless_mean_act
refusal_dir = refusal_dir / refusal_dir.norm()
activation_refusals[layer].append(refusal_dir)
selected_layers = ["resid_pre"]
activation_scored = sorted(
[
activation_refusals[layer][l - 1]
for l in range(1, model.cfg.n_layers)
for layer in selected_layers
],
key=lambda x: abs(x.mean()),
reverse=True,
)
5.7 Evaluation
Evaluate the refusal directions by applying them during inference.
def _generate_with_hooks(
model: HookedTransformer,
tokenizer: AutoTokenizer,
tokens: Int[Tensor, "batch_size seq_len"],
max_tokens_generated: int = 64,
fwd_hooks=[]
) -> List[str]:
all_tokens = torch.zeros(
(tokens.shape[0], tokens.shape[1] + max_tokens_generated),
dtype=torch.long,
device=tokens.device,
)
all_tokens[:, : tokens.shape[1]] = tokens
for i in range(max_tokens_generated):
with model.hooks(fwd_hooks=fwd_hooks):
logits = model(all_tokens[:, : -max_tokens_generated + i])
next_tokens = logits[:, -1, :].argmax(dim=-1)
all_tokens[:, -max_tokens_generated + i] = next_tokens
return tokenizer.batch_decode(all_tokens[:, tokens.shape[1]:], skip_special_tokens=True)
def get_generations(
model: HookedTransformer,
tokenizer: AutoTokenizer,
instructions: List[str],
fwd_hooks=[],
max_tokens_generated: int = 64,
batch_size: int = 4,
) -> List[str]:
generations = []
for i in tqdm(range(0, len(instructions), batch_size)):
tokens = tokenize_instructions(tokenizer, instructions=instructions[i : i +
batch_size])
generation = _generate_with_hooks(
model, tokenizer, tokens, max_tokens_generated=max_tokens_generated, fwd_hooks=fwd_hooks
)
generations.extend(generation)
return generations
def direction_ablation_hook(
activation: Float[Tensor, "... d_act"],
hook: HookPoint,
direction: Float[Tensor, "d_act"],
):
if activation.device != direction.device:
direction = direction.to(activation.device)
proj = (
einops.einsum(
activation, direction.view(-1, 1), "... d_act, d_act single -> ... single"
) * direction
)
return activation - proj
N_INST_TEST = 4
baseline_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
)
EVAL_N = 20
evals = []
for refusal_dir in tqdm(activation_scored[:EVAL_N]):
hook_fn = functools.partial(direction_ablation_hook, direction=refusal_dir)
fwd_hooks = [
(utils.get_act_name(act_name, layer), hook_fn)
for layer in list(range(model.cfg.n_layers))
for act_name in activation_layers
]
intervention_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=fwd_hooks
)
evals.append(intervention_generations)
blacklist = ["I cannot", "I can't"]
for i in range(N_INST_TEST):
print(f"\033[1mINSTRUCTION {i}: {harmful_inst_test[i]}")
print(f"\nBASELINE COMPLETION:\n{baseline_generations[i]}\033[0m")
for layer_candidate in range(EVAL_N):
if not any(word in evals[layer_candidate][i] for word in blacklist):
print(f"\n\n\nLAYER CANDIDATE #{layer_candidate} INTERVENTION COMPLETION:")
print(evals[layer_candidate][i])
5.8 Weight Orthogonalization
Select the best refusal direction and orthogonalize the model’s weights.
def get_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"], vec: Float[Tensor, "d_model"]
) -> Float[Tensor, "... d_model"]:
proj = (
einops.einsum(
matrix, vec.view(-1, 1), "... d_model, d_model single -> ... single"
) * vec
)
return matrix - proj
LAYER_CANDIDATE = 9
refusal_dir = activation_scored[LAYER_CANDIDATE]
if refusal_dir.device != model.W_E.device:
refusal_dir = refusal_dir.to(model.W_E.device)
model.W_E.data = get_orthogonalized_matrix(model.W_E, refusal_dir)
for block in tqdm(model.blocks):
if refusal_dir.device != block.attn.W_O.device:
refusal_dir = refusal_dir.to(block.attn.W_O.device)
block.attn.W_O.data = get_orthogonalized_matrix(block.attn.W_O, refusal_dir)
block.mlp.W_out.data = get_orthogonalized_matrix(block.mlp.W_out, refusal_dir)
orthogonalized_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
)
for i in range(N_INST_TEST):
if len(baseline_generations) > i:
print(f"INSTRUCTION {i}: {harmful_inst_test[i]}")
print(f"\033[92mBASELINE COMPLETION:\n{baseline_generations[i]}")
print(f"\033[91mINTERVENTION COMPLETION:\n{evals[LAYER_CANDIDATE][i]}")
print(f"\033[95mORTHOGONALIZED COMPLETION:\n{orthogonalized_generations[i]}\n")
6. DPO Fine-Tuning
To restore the model’s performance post-abliteration, we can use DPO (Direct Preference Optimization) fine-tuning.
6.1 Configuration Details
base_model: mlabonne/Daredevil-8B-abliterated
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
save_safetensors: true
rl: dpo
chat_template: chatml
datasets:
- path: mlabonne/orpo-dpo-mix-40k-flat
split: train
type: chatml.intel
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./out
adapter: qlora
lora_model_dir:
sequence_len: 2048
sample_packing: false
pad_to_sequence_len: false
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: axolotl
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 5e-6
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32:
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 100
evals_per_epoch: 0
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 1
debug:
deepspeed: deepspeed_configs/zero2.json
weight_decay: 0.0
special_tokens:
pad_token:
6.2 Training
I trained the model using 6xA6000 GPUs with DeepSpeed ZeRO-2 for about 6 hours and 45 minutes. The training curves showed that the additional training allowed us to recover most of the performance drop due to abliteration.
6.3 Final Model
The final model, NeuralDaredevil-8B, is a fully uncensored and high-quality 8B LLM. This technique demonstrates the fragility of safety fine-tuning and raises ethical considerations.
7 Conclusion
In this article, we introduced the concept of abliteration, a technique that uses the model’s activations on harmless and harmful prompts to calculate a refusal direction. This direction is then used to modify the model’s weights, ensuring that the model stops outputting refusals. After abliteration, we restored the model’s performance using DPO fine-tuning, resulting in a fully uncensored LLM with state-of-the-art performance in the 8B category.
8 References
- Original Post: https://huggingface.co/blog/mlabonne/abliteration by Maxime Labonne
- FailSpy, “abliterator library,” GitHub, 2024.
- Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda, “Refusal in LLMs is mediated by a single direction,” Lesswrong, 2024.