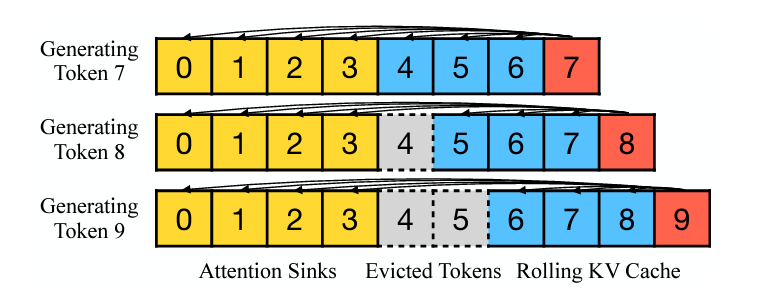
Attention Sinks
- Related Project: Private
- Category: Paper Review
- Date: 2023-10-01
Efficient Streaming Language Models with Attention Sinks
- url: https://arxiv.org/abs/2309.17453v1
- pdf: https://arxiv.org/pdf/2309.17453v1
- abstract: Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens’ Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. attention window, where only the most recent KVs are cached, is a natural approach - but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink’’ even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at this https URL.
Contents
TL;DR
- 스트리밍 대규모 언어모델 (LLM) 제안: 무한 길이 입력에 대해 효율적이고 정확하게 작동할 수 있도록 설계된 새로운 LLM 프레임워크
- 기존 기술 한계 극복: 입력 길이가 늘어날 때 성능 저하 문제를 해결하고, 계산 효율을 유지하면서 지속적으로 LLM을 스트리밍할 수 있는 방법을 개발
- 초기 토큰이 ‘주의(어텐션) 집중’ 역할을 하는 현상을 수학적으로 설명하고 이를 활용하여 성능을 향상시키는 방법을 제시
[초기 토큰의 주의 집중 관련 색인마킹]
Attention Sink에 대한 비교 분석에 대한 Tomaarsen의 깃 허브 레포지토리가 있습니다. 질문에 대한 답변을 보면, 결론적으로 Context Window를 초과하는 토큰이 생성된 후에 인퍼런스 속도가 full/dense attention보다 약간 더 빨라지는 경향성이 있으나 Attention Sinks를 적용해 가중치를 고르게 분산하는 것이 약간의 성능 손실이 유발한다고 합니다.
즉, Attention Sinks로 전반적인 가중치를 고르게 분산시키는 것이 전반적인 LLM 모델의 이해도를 떨어트리는 작업이 될 수 있고, 이 논문에서 제시한 시퀀스 초기 토큰에 대한 가중치가 더 많이 실리는 것은 문제가 아니라 Attention 메카니즘의 특성상 전반적인 자연어의 시퀀스 초기에 가중치를 더 두는 것이 자연어 이해에 더 도움이 될 수 있음을 의미할 수 있습니다.
그 외 논문 작업에 대한 후속 작업을 진행한 것으로 보이는데 레포지토리에 코드와 함께 설명되어 있습니다.
1 서론
대규모 언어모델들(LLMs)은 대화 시스템, 문서 요약, 코드 완성, 질의 응답 등 다양한 자연어 처리 응용 프로그램에 활용되고 있습니다. 이런 모델들이 효과적으로 작동하기 위해서는 훈련된 것보다 긴 시퀀스를 효율적이고 정확하게 생성할 수 있어야 합니다. 현재 LLM들은 attention window(attention window) 크기에 의해 제한을 받고 있으며, 이는 긴 입력에 대한 일반화를 어렵게 만듭니다. 본 논문에서는 LLM이 무한 길이의 입력에 대해 효율적이고 성능 저하 없이 작동할 수 있는지를 탐구합니다.
2 관련 연구
이 섹션에서는 긴 텍스트를 처리하기 위한 대규모 언어모델에 대한 연구를 세 가지 주요 영역으로 나누어 설명합니다.
- 길이 외삽: 짧은 텍스트에서 훈련된 언어 모델이 테스트 시 더 긴 텍스트를 처리할 수 있도록 하는 방법.
- Context 창 확장: LLM의 Context 창을 확장하여 한 번의 전방 패스에서 더 많은 토큰을 처리할 수 있도록 하는 기술.
- 긴 텍스트의 활용 개선: 단순히 긴 텍스트를 입력으로 사용하는 것이 아니라, LLM이 긴 문맥의 내용을 효과적으로 포착하고 활용하도록 최적화하는 연구.
본 연구는 첫 번째 영역, 즉 긴 텍스트에 대한 LLM의 적용을 주로 다루며, 무한 길이 외삽의 가능성을 탐구합니다.
3 스트리밍 LLM
3.1 attention window와 어텐션 집중 실패 분석
attention window 기법은 인퍼런스 동안 효율적이지만, 언어 모델의 복잡도가 높아지면 성능이 급격히 떨어지는데, 이는 초기 토큰의 키(Key)와 값(Value) 상태를 제거할 때 발생하는 현상으로 알려져있습니다. 이런 초기 토큰들이 모델의 안정성을 유지하는 데 중요한 역할을 하며, 그들이 ‘어텐션 집중’의 역할을 함으로써 어텐션 점수 분포를 정상적으로 유지합니다.
\[\text{Softmax}(Q, K, V) = \text{Attention}(Q, K) V\]상기 수식에서 \(Q, K, V\)는 각각 질의(query), 키(key), 값(value) 벡터를 나타냅니다. 초기 토큰들이 제거되면, Softmax 함수의 분모가 변하고, 이는 어텐션 점수 분포의 이상을 초래하여 성능 저하로 이어집니다.
3.2 스트리밍 LLM 방법
스트리밍 LLM은 초기 토큰들을 유지함으로써 어텐션 메커니즘을 안정화시키고, 이를 통해 모델이 무한 길이의 입력을 처리할 수 있도록 합니다. 이는 스트리밍 어플리케이션에서 LLM의 지속적인 사용을 가능하게 합니다. 실험을 통해 어텐션 집중 토큰을 유지하는 것만으로도 언어 모델의 성능을 유지할 수 있음을 보여줬습니다.
3.3 실험과 결과
본 논문에서는 Llama-2 모델을 사용하여 스트리밍 LLM의 성능을 실험적으로 검증합니다. 어텐션 집중 토큰이 포함된 스트리밍 LLM은 전통적인 모델들에 비해 훨씬 높은 속도와 안정적인 성능을 보여줍니다. 이런 결과는 스트리밍 LLM이 실제 언어 모델 응용 프로그램에 적합함을 시사합니다.
1 Introduction
Large Language Models (LLMs) (Radford et al., 2018; Brown et al., 2020; Zhang et al., 2022; OpenAI, 2023; Touvron et al., 2023a; b) are becoming ubiquitous, powering many natural language processing applications such as dialog systems (Schulman et al., 2022; Taori et al., 2023; Chang et al., 2023), document summarization (Goyal & Durrett, 2020; Zhang et al., 2023a), code completion (Chen et al., 2021; Rozière et al., 2023), and question answering (Kamalloo et al., 2023). To unleash the full potential of pretrained LLMs, they should be able to efficiently and accurately perform long sequence generation. For example, an ideal ChatBot assistant can stably work over the content of recent day-long conversations. However, it is very challenging for LLMs to generalize to longer sequence lengths than they have been pretrained on, e.g., 4K for Llama-2 (Touvron et al., 2023b). The reason is that LLMs are constrained by the attention window during pre-training. Despite substantial efforts to expand this window size (Chen et al., 2023; kaioken dev, 2023; Peng et al., 2023) and improve training (Dao et al., 2022; Dao, 2023) and inference (Pope et al., 2022; Xiao et al., 2023; Anagnostidis et al., 2023; Zhang et al., 2023b) efficiency for lengthy inputs, the acceptable sequence length remains intrinsically finite, which doesn’t allow persistent deployments. In this paper, we first introduce the concept of LLM streaming applications and ask the question: Can we deploy an LLM for infinite-length inputs without sacrificing efficiency and performance?
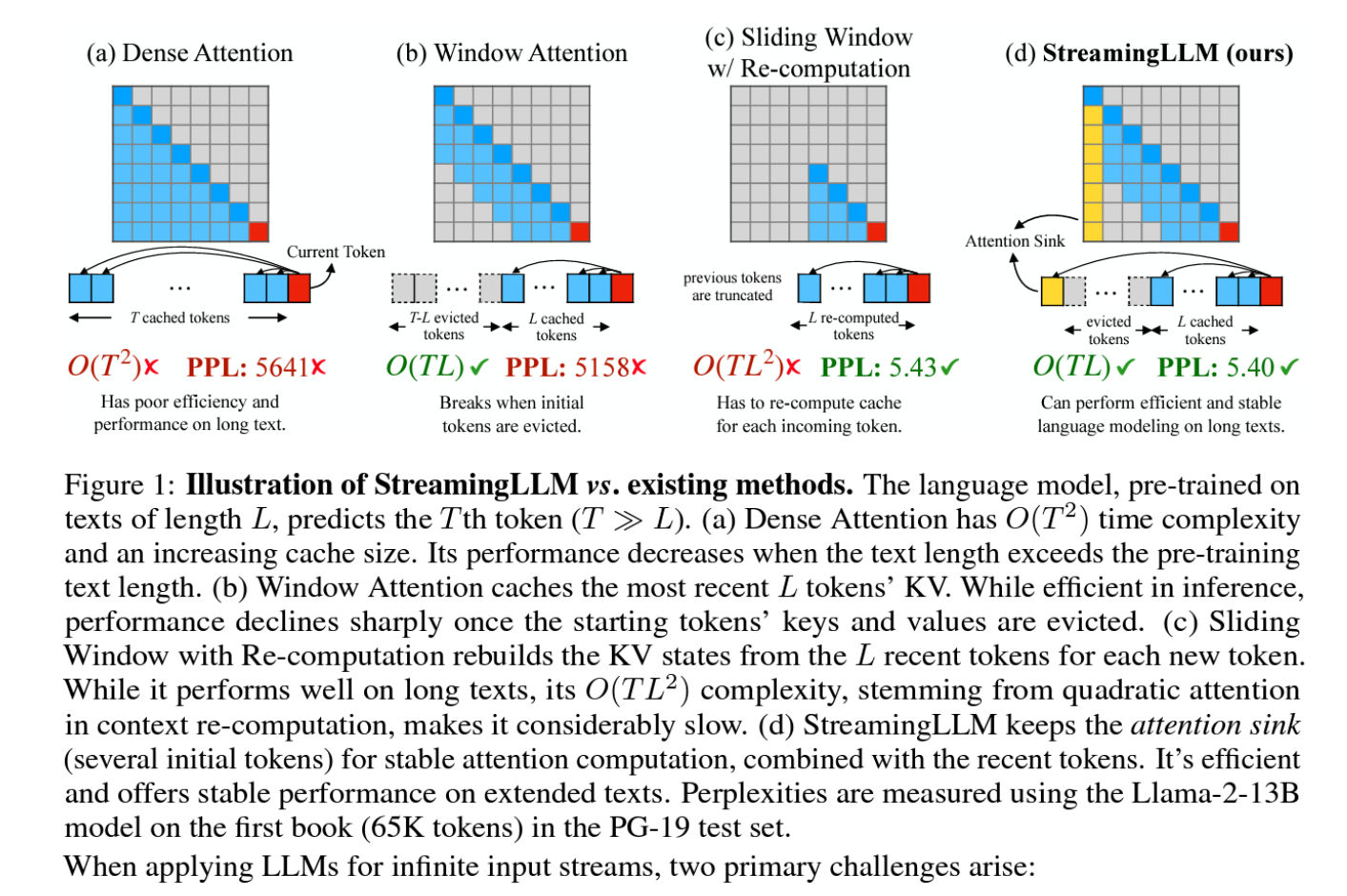
Figure 1: Illustration of Streaming LLM vs. existing methods. The language model, pre-trained on texts of length L, predicts the Tth token (T ≫ L). (a) Dense Attention has O(T^2) time complexity and an increasing cache size. Its performance decreases when the text length exceeds the pre-training text length. (b) Window Attention caches the most recent L tokens’ KV. While efficient in inference, performance declines sharply once the starting tokens’ keys and values are evicted. (c) Sliding Window with Re-computation rebuilds the KV states from the L recent tokens for each new token. While it performs well on long texts, its O(TL^2) complexity, stemming from quadratic attention in context re-computation, makes it considerably slow. (d) Streaming LLM keeps the attentions in k (several initial tokens) for stable attention computation, combined with the recent tokens. It’s efficient and offers stable performance on extended texts. Perplexities are measured using the Llama-2-13B model on the first book (65K tokens) in the PG-19 test set.
When applying LLMs for infinite input streams, two primary challenges arise:
-
During the decoding stage, Transformer-based LLMs cache the Key and Value states (KV) of all previous tokens, as illustrated in Figure 1(a), which can lead to excessive memory usage and increasing decoding latency (Pope et al., 2022).
-
Existing models have limited length extrapolation abilities, i.e., their performance degrades (Press et al., 2022; Chen et al., 2023) when the sequence length goes beyond the attention window sizes set during pre-training.
An intuitive approach, known as window attention (Beltagy et al., 2020) (Figure 1b), maintains only a fixed-size sliding window on the KV states of most recent tokens. Although it ensures constant memory usage and decoding speed after the cache is initially filled, the model collapses once the sequence length exceeds the cache size, i.e., even just evicting the KV of the first token, as illustrated in Figure 3.
Another strategy is the sliding window with re-computation (shown in Figure 1c), which rebuilds the KV states of recent tokens for each generated token. While it offers strong performance, this approach is significantly slower due to the computation of quadratic attention within its window, making this method impractical for real-world streaming applications.
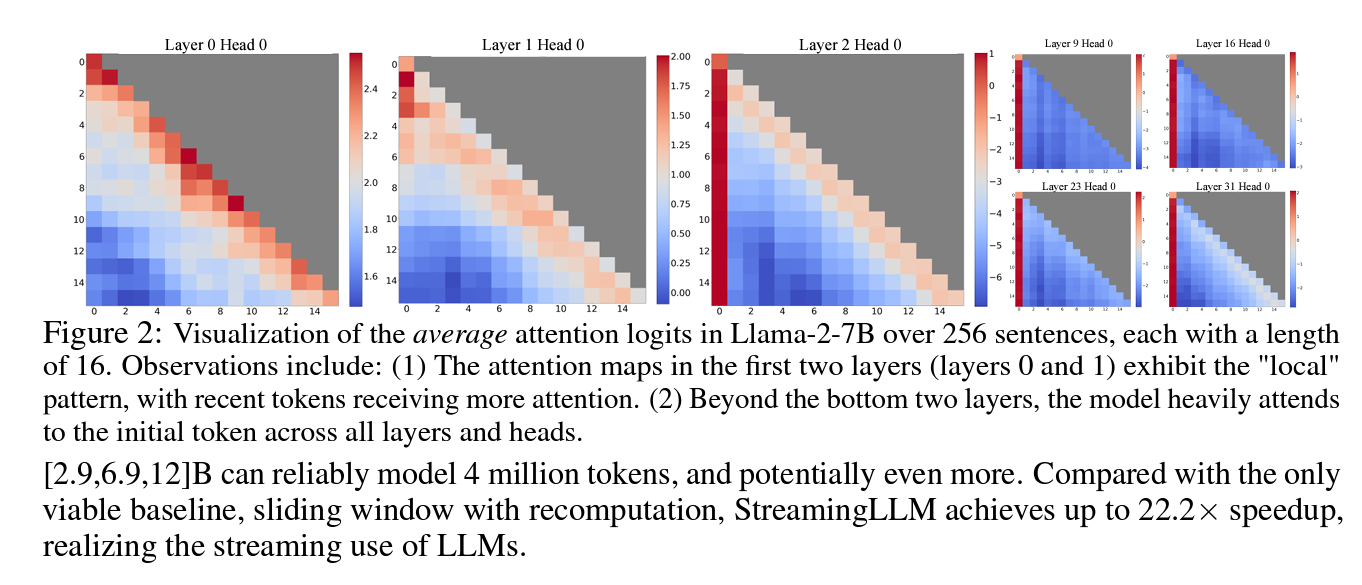
Figure 2: Visualization of the average attention logits in Llama-2-7B over 256 sentences, each with a length of 16. Observations include:
- The attention maps in the first two layers (layers 0 and 1) exhibit the “local” pattern, with recent tokens receiving more attention.
- Beyond the bottom two layers, the model heavily attends to the initial token across all layers and heads.
[2.9,6.9,12]B can reliably model 4 million tokens, and potentially even more. Compared with the only viable baseline, sliding window with recomputation, Streaming LLM achieves up to a 22.2× speedup, realizing the streaming use of LLMs.
To understand the failure of window attention, we find an interesting phenomenon in autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens “attention sinks.” Despite their lack of semantic significance, they collect significant attention scores. We attribute this phenomenon to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
Based on the above insights, we propose Streaming LLM, a simple and efficient framework that enables LLMs trained with a finite attention window to work on context of infinite length without fine-tuning. Streaming LLM exploits the fact that attention sink tokens have high attention values, and preserving them can maintain the attention score distribution close to normal. Therefore, Streaming LLM simply keeps the attention sink tokens’ KV (with just 4 initial tokens sufficing) together with the sliding window’s KV to anchor the attention computation and stabilize the model’s performance. With Streaming LLM, models including Llama-2-[7,13,70]B, MPT-[7,30]B, Falcon-[7,40]B, and Pythia Finally, we confirm our attention sink hypothesis and demonstrate that language models can be pre-trained to require only a single attention sink token for streaming deployment. Specifically, we suggest that an extra learnable token at the beginning of all training samples can serve as a designated attention sink. By pre-training 160-million-parameter language models from scratch, we demonstrate that adding this single sink token preserves the model’s performance in streaming cases. This stands in contrast to vanilla models, which necessitate the reintroduction of multiple initial tokens as attention sink tokens to achieve the same performance level.
2 Related Work
Extensive research has been conducted on applying Large Language Models (LLMs) to handle lengthy texts, focusing on three main areas: Length Extrapolation, Context Window Extension, and Improving LLMs’ Utilization of Long Text. It’s important to note that progress in one area doesn’t necessarily lead to progress in the others. Our Streaming LLM framework primarily falls under the first category, which involves applying LLMs to texts significantly exceeding their pre-training window size, potentially even of infinite length. We do not aim to expand the attention window size of LLMs or enhance their memory and usage on long texts. The last two categories are orthogonal to our focus and could potentially be integrated with our techniques.
-
Length Extrapolation: This area focuses on enabling language models trained on short texts to handle longer ones during testing. Researchers have explored methods like Rotary Position Embeddings (RoPE) and biased query-key attention scores based on their distance to introduce relative positional information. However, existing methodologies have yet to achieve infinite length extrapolation, making them unsuitable for streaming applications.
-
Context Window Extension: This area centers on expanding the context window of LLMs to process more tokens in a single forward pass. Various techniques have been proposed to address the computational and memory challenges associated with long-context LLMs. These include system-focused optimizations like FlashAttention, approximate attention methods, and extending pre-trained LLMs with RoPE. However, these techniques only extend LLMs’ context window to a limited extent, falling short of handling limitless inputs.
-
Improving LLMs’ Utilization of Long Text: This area focuses on optimizing LLMs to better capture and utilize the content within lengthy contexts rather than merely taking them as inputs. Success in the previous two directions doesn’t necessarily lead to effective usage of prolonged contexts within LLMs. Our work, on the other hand, concentrates on stably harnessing the most recent tokens, enabling the seamless streaming application of LLMs.
3 Streaming LLM
3.1 The failure of window attention and attention sinks
While the window attention technique offers efficiency during inference, it results in an exceedingly high language modeling perplexity. Consequently, the model’s performance is unsuitable for deployment in streaming applications. In this section, we use the concept of attention sink to explain the failure of window attention, serving as the inspiration behind Streaming LLM.
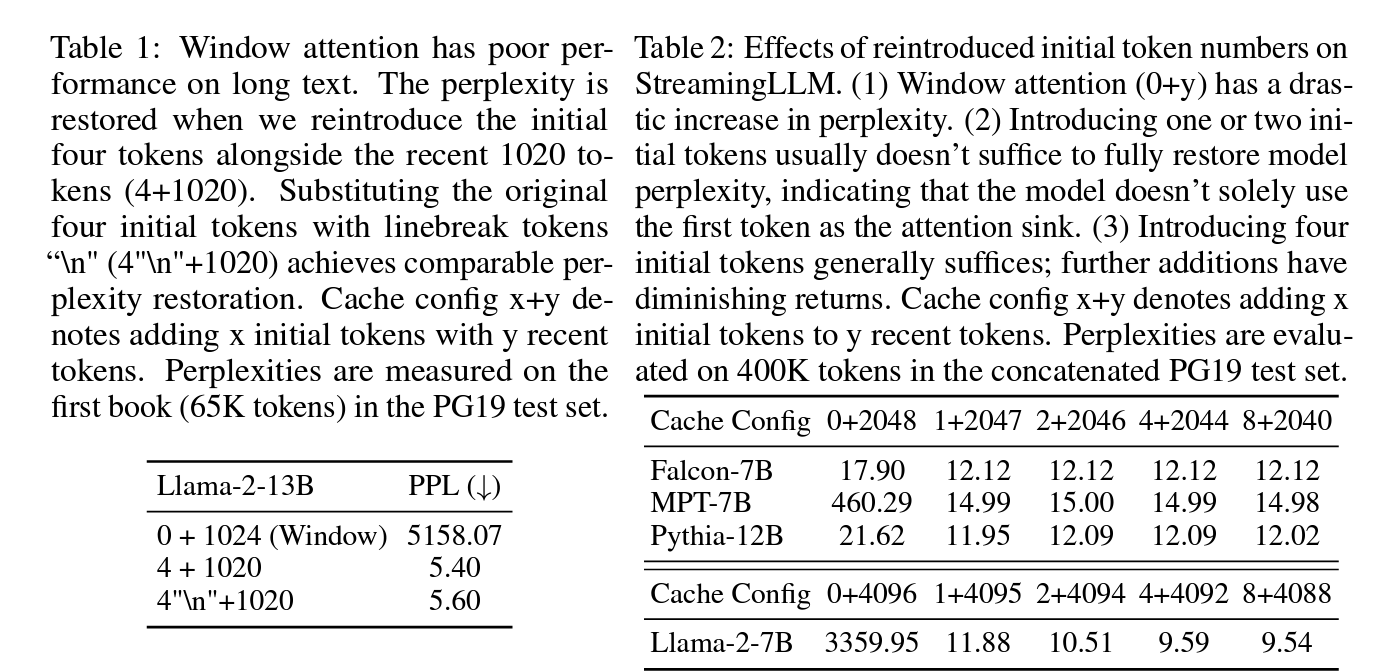
Identifying the Point of Perplexity Surge: Figure 3 shows the perplexity of language modeling on a 20K token text. It is evident that perplexity spikes when the text length surpasses the cache size, led by the exclusion of initial tokens. This suggests that the initial tokens, regardless of their distance from the tokens being predicted, are crucial for maintaining the stability of LLMs.
Why do LLMs break when removing initial tokens’ KV? We visualize attention maps from all layers and heads of the Llama-2-7B and models in Figure 2. We find that, beyond the bottom two layers, the model consistently focuses on the initial tokens across all layers and heads. The implication is clear: removing these initial tokens’ KV will remove a considerable portion of the denominator in the SoftMax function (Equation 1) in attention computation. This alteration leads to a significant shift in the distribution of attention scores away from what would be expected in normal inference settings.
There are two possible explanations for the importance of the initial tokens in language modeling: (1) Either their semantics are crucial, or (2) the model learns a bias towards their absolute position. To distinguish between these possibilities, we conduct experiments (Table 1), where in the first four tokens are substituted with the linebreak token “\n”. The observations indicate that the model still significantly emphasizes these initial linebreak tokens. Furthermore, reintroducing them restores the language modeling perplexity to levels comparable to having the original initial tokens. This suggests that the absolute position of the starting tokens, rather than their semantic value, holds greater significance.
LLMs attend to Initial Tokens as Attention Sinks: To explain why the model disproportionately focuses on initial tokens—regardless of their semantic relevance to language modeling, we introduce the concept of “attention sink”. The nature of the SoftMax function (Equation 1) prevents all attended tokens from having zero values. This requires aggregating some information from other tokens across all heads in all layers, even if the current embedding has sufficient self-contained information for its prediction. Consequently, the model tends to dump unnecessary attention values to specific tokens. A similar observation has been made in the realm of quantization outliers (Xiao et al., 2023; Bondarenko et al., 2023), leading to the proposal of SoftMax-Off-by-One (Miller, 2023) as a potential remedy.
Why do various autoregressive LLMs, such as Llama-2, MPT, Falcon, and Pythia, consistently focus on initial tokens as their attention sinks, rather than other tokens? Our explanation is straightforward: Due to the sequential nature of autoregressive language modeling, initial tokens are visible to all subsequent tokens, while later tokens are only visible to a limited set of subsequent tokens. As a result, initial tokens are more easily trained to serve as attention sinks, capturing unnecessary attention.
We’ve noted that LLMs are typically trained to utilize multiple initial tokens as attention sinks rather than just one. As illustrated in Figure 2, the introduction of four initial tokens, as attention sinks, suffices to restore the LLM’s performance. In contrast, adding just one or two doesn’t achieve full recovery. We believe this pattern emerges because these models didn’t include a consistent starting token across all input samples during pre-training. Although Llama-2 does prefix each paragraph with a <s> token, it’s applied before text chunking, resulting in a mostly random token occupying the zeroth position. This lack of a uniform starting token leads the model to use several initial tokens as attention sinks. We hypothesize that by incorporating a stable, learnable token at the start of all training samples, it could singularly act as a committed attention sink, eliminating the need for multiple initial tokens to ensure consistent streaming. We will validate this hypothesis in Section 3.3.
3.2 ROLLING K,V,CACHE WITH ATTENTION SINKS